[컴퓨터 비전의 모든 것] Conditional Generative Model
2024. 12. 20. 04:00ㆍMOOC
Conditional Generative Model
What is a Conditional Generative Model?
Conditional Generative Model은 조건(condition)에 따라 데이터를 생성하는 모델이다.
예를 들어, 가방의 스케치가 주어졌을 때 이를 실제 가방 이미지로 변환하는 image-to-image translation 작업이 Conditional Generative Model의 대표적인 예다.

주요 특징:
- 조건 기반 생성
- 단순 랜덤 생성이 아닌, 입력된 조건(예: 스케치)을 반영하여 데이터 생성.
- 사용자 의도가 반영된 유용한 결과를 생성 가능.
- 확률 분포 모델링
- Generative Model은 데이터의 확률 분포를 모델링하며, Conditional Model은 조건에 따라 해당 분포에서 샘플링을 수행한다.
응용 사례:
- Vision Task:
- Image Translation (스케치 → 이미지 변환).
- Super Resolution (저해상도 → 고해상도 변환).
- Colorization (흑백 → 컬러 변환).
- Audio Task: 저음질 → 고음질 변환.
- Natural Language Processing: 제목 → 기사 생성, 언어 번역.
Generative Adversarial Networks (GAN)
GAN의 학습 과정은 종종 위조지폐범과 경찰에 비유된다:
- Generator (위조지폐범): 진짜처럼 보이는 데이터를 생성.
- Discriminator (경찰): 진짜 데이터와 생성된 데이터를 구별.

학습 과정:
- Generator는 Discriminator를 속이기 위해 더욱 진짜같은 데이터를 생성하도록 학습된다.
- Discriminator는 위조 데이터를 정확히 구별하도록 학습된다.
- 이 적대적 상호작용을 통해 GAN은 점점 더 높은 품질의 데이터를 생성하게 된다.
Conditional GAN (cGAN)
Conditional GAN은 Vanilla GAN의 확장으로, 조건(condition)을 입력으로 추가하여 데이터를 생성한다.
주요 차이점:
- Condition Input:
- Vanilla GAN은 latent vector zz만을 입력으로 사용.
- cGAN은 zz와 함께 조건 cc를 추가 입력으로 사용.
- 구조는 유사:
- 나머지 학습 과정은 Vanilla GAN과 동일하다.

Conditional GAN and Image Translation
대표적인 응용:
- Style Transfer:
- 입력 이미지의 스타일을 유명 화가(예: 모네, 반 고흐)의 스타일로 변환.
- Super Resolution:
- 저해상도 이미지를 고해상도로 변환.
- Colorization:
- 흑백 이미지를 컬러로 변환.

Super Resolution with cGAN
Super Resolution Task:
- 입력: 저해상도 이미지.
- 출력: 고해상도 이미지.
- 구조:
- Generator: 저해상도 이미지를 입력받아 고해상도 이미지를 생성.
- Discriminator:
- Real Data: 실제 고해상도 이미지.
- Fake Data: Generator가 생성한 고해상도 이미지.
- 두 데이터를 비교하여 진짜인지 가짜인지 판별.
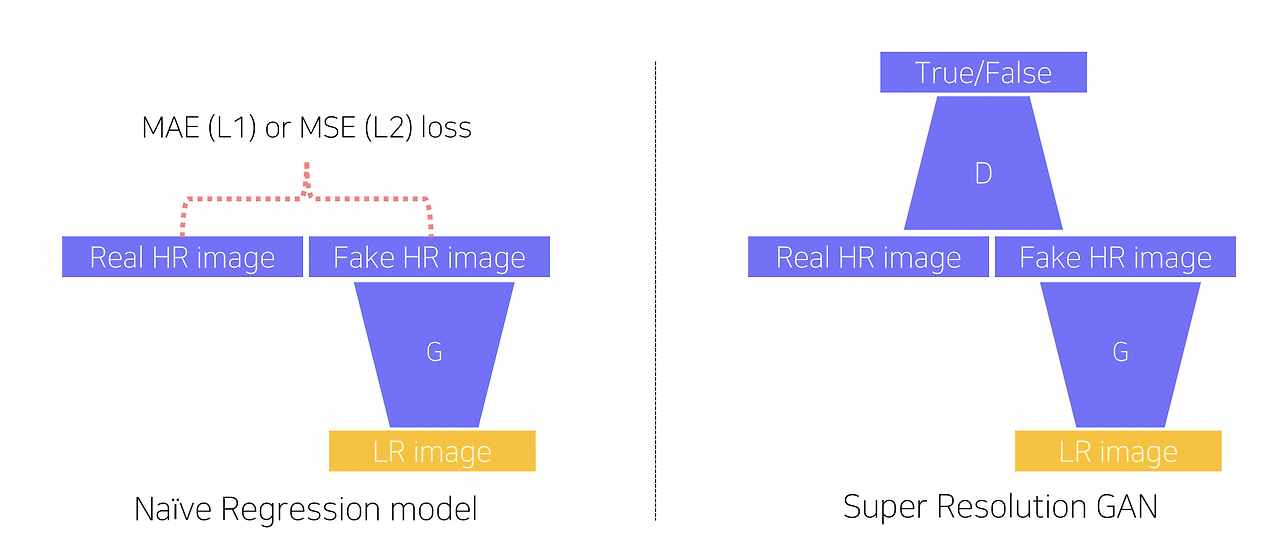
Loss Functions in Super Resolution:
- MAE (Mean Absolute Error):
- Prediction과 Ground Truth 간의 절대 차이의 평균.
- 단순하고 직관적인 손실 함수.
- MSE (Mean Squared Error):
- Prediction과 Ground Truth 간의 제곱 차이의 평균.
- 픽셀 차이를 기반으로 학습.

한계:
- MSE/MAE 기반 모델:
- 해상도는 높아지지만, 결과 이미지가 흐릿해지는 경향이 있음.
- 이유: 평균적인 픽셀 값을 생성하도록 학습되기 때문.
- GAN 기반 모델:
- Discriminator가 흐릿한 결과를 판별하여 Generator가 보다 현실적이고 선명한 이미지를 생성하도록 학습.
- 예: SRGAN은 MSE 기반 모델보다 선명하고 생생한 결과를 생성.
'MOOC' 카테고리의 다른 글
| [머신러닝을 위한 파이썬] pythonic code 2 (0) | 2024.12.22 |
|---|---|
| [머신러닝을 위한 파이썬] Pythonic Code (2) | 2024.12.22 |
| [컴퓨터 비전의 모든 것] Detecting Objects as Keypoints (1) | 2024.12.20 |
| [컴퓨터 비전의 모든 것] Panoptic Segmentation & Landmark Localization (0) | 2024.12.20 |
| [컴퓨터 비전의 모든 것] Instance Segmentation (3) | 2024.12.20 |