2025. 7. 1. 19:35ㆍ카테고리 없음
1. 멀티레벨 스태킹 (Multi-Level Stacking)
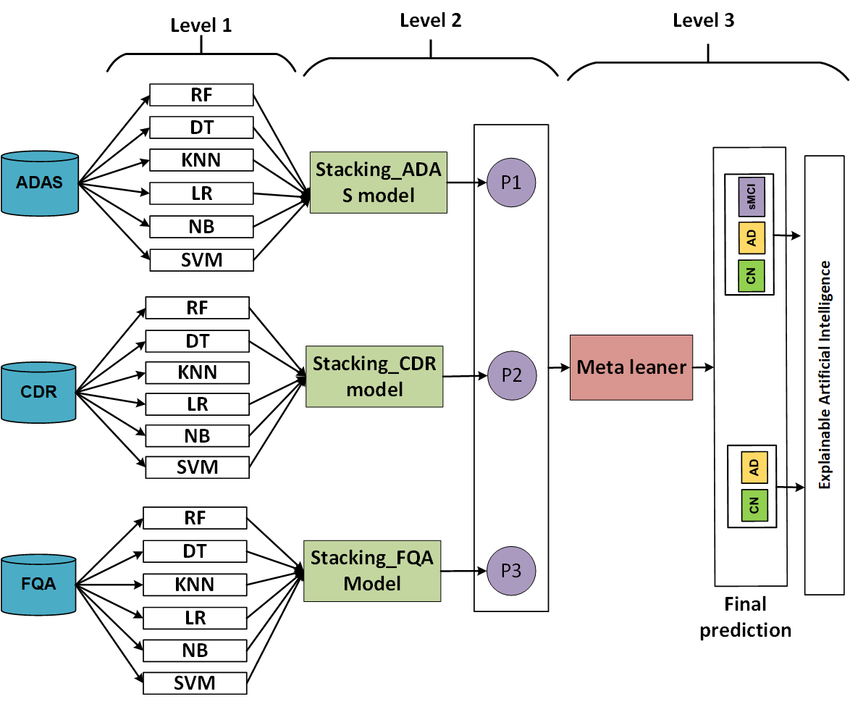
멀티레벨 스태킹은 스태킹의 확장으로 스태킹을 여러 레이어에 적용하는 기법이다. 멀티레이어 스택은 여러 층의 베이스 모델을 사용하며, 중첩된 스택을 통해 달성할 수 있다.
작동 원리:
- Level 0: 원본 데이터로 학습하는 베이스 모델들
- Level 1: Level 0 모델들의 예측을 입력으로 받는 메타 모델
- Level 2: Level 1 모델들의 예측을 입력으로 받는 최종 모델
최신 연구 사례: 2025년 연구에서 급성 뇌졸중 환자의 입원 기간 예측을 위해 SHAP 기반의 설명 가능한 멀티레벨 스태킹 앙상블 모델이 개발되었으며, 허혈성 뇌졸중에서 AUC 0.843을 달성했다.
장점
- 점진적 성능 향상: 각 레벨에서 이전 레벨의 오류를 보정하여 단계적으로 성능 개선
- 복잡한 패턴 학습: 여러 추상화 레벨을 통해 더 미묘하고 복합적인 데이터 패턴 포착
- 강건성: 하위 레벨 모델의 일부 실패가 상위 레벨에서 보정 가능
- 모듈화: 각 레벨을 독립적으로 설계하고 최적화 가능
단점
- 계산 복잡도 급증: 레벨 증가에 따른 훈련 시간과 메모리 요구량 기하급수적 증가
- 과적합 위험: 모델 복잡도 증가로 인한 과적합 가능성 높아짐
- 데이터 희석: 각 레벨마다 K-fold로 인한 유효 훈련 데이터 감소
- 디버깅 어려움: 문제 발생 시 원인 레벨 파악이 복잡
2. 어텐션 기반 앙상블 (Attention-Based Ensemble)

어텐션 메커니즘을 기반으로 한 새로운 스태킹 앙상블 학습 모델이 제안되었으며, 베이스 모델과 메타 모델의 2층 구조를 가진다.
특징:
- 베이스 모델: Random Forest, AdaBoost, XGBoost
- 메타 모델: 어텐션 메커니즘을 사용하여 베이스 모델들의 출력을 통합
- 성능: XGBoost 대비 10.22%, 가중 평균 앙상블 대비 8.54% 성능 향상
장점
- 적응적 가중치: 입력에 따라 각 모델의 기여도를 동적으로 조정
- 우수한 성능: XGBoost 대비 10.22% 성능 향상 입증
- 효율적 통합: 어텐션 메커니즘으로 베이스 모델들의 최적 조합 자동 학습
- 해석 가능성: 어텐션 가중치를 통해 각 모델의 기여도 시각화 가능
단점
- 계산 오버헤드: 어텐션 메커니즘으로 인한 추가 계산 비용
- 하이퍼파라미터 복잡성: 어텐션 네트워크의 아키텍처 설계 및 튜닝 필요
- 데이터 의존성: 효과적인 어텐션 학습을 위해 충분한 데이터 필요
- 상대적 신기술: 검증된 사례가 제한적이고 안정성 확신 어려움
3. 블렌딩 (Blending)

블렌딩은 스태킹과 거의 유사하지만 한 가지 차이점이 있다. 스태킹은 학습 세트에 대해 out-of-fold 예측을 사용하는 반면, 블렌딩은 홀드아웃(검증) 세트(학습 세트의 10-20%)를 사용하여 다음 레이어를 학습한다.
블렌딩 vs 스태킹:
- 블렌딩: 홀드아웃 세트 사용, 더 간단, 적은 데이터 사용
- 스태킹: K-fold 교차검증 사용, 더 복잡, 더 많은 데이터 활용
장점
- 구현 간편성: 스태킹 대비 단순한 구조로 구현과 이해가 쉬움
- 빠른 훈련: K-fold 교차검증 없이 홀드아웃 세트만 사용하여 시간 절약
- 메모리 효율: 적은 데이터 사용으로 메모리 요구량 감소
- 과적합 방지: 상대적으로 단순한 구조로 과적합 위험 낮음
단점
- 데이터 낭비: 홀드아웃 세트(10-20%)를 훈련에 사용하지 못함
- 성능 한계: 스태킹 대비 일반적으로 낮은 성능
- 홀드아웃 과적합: 특정 홀드아웃 세트에 과적합될 위험
- 일반화 부족: K-fold 대비 모델의 일반화 성능이 떨어질 수 있음
4. 동적 가중치 앙상블 (Dynamic Weighted Ensemble)
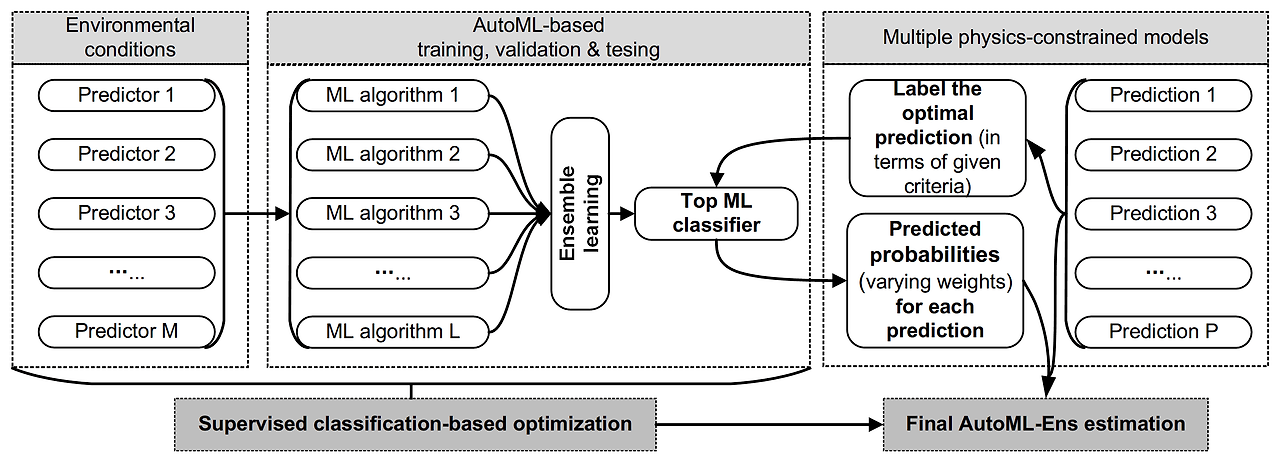
전통적인 고정 가중치 대신 입력 데이터에 따라 동적으로 가중치를 조정하는 기법이다.
특징:
- 각 예측에 대해 모델별로 다른 가중치 적용
- 메타러닝을 통해 최적 가중치 학습
- 데이터의 지역적 특성에 따른 적응적 예측
장점
- 적응성: 입력 데이터의 특성에 따라 최적 모델 조합 동적 선택
- 지역적 최적화: 데이터 공간의 서로 다른 영역에서 서로 다른 모델 강조
- 유연성: 고정 가중치의 한계를 극복하여 더 정교한 예측
- 개별화: 각 예측 인스턴스에 맞춤형 모델 조합 적용
단점
- 복잡한 학습: 메타러닝을 통한 가중치 학습 과정이 복잡
- 계산 비용: 각 예측마다 가중치 계산으로 인한 추론 시간 증가
- 불안정성: 동적 가중치로 인한 예측 결과의 일관성 부족 가능
- 해석 어려움: 가중치 변화 패턴을 이해하고 설명하기 어려움
5. 딥러닝 기반 앙상블

신경망을 서브모델로 사용하고 scikit-learn 분류기를 메타러너로 사용하는 스태킹 모델이 개발되고 있다.
구성:
- 서브모델: 여러 개의 신경망(MLP, CNN, RNN 등)
- 메타모델: 전통적인 ML 알고리즘 또는 다른 신경망
- 학습: K-fold 교차검증으로 메타모델 학습
장점
- 표현력: 신경망의 강력한 비선형 표현 능력 활용
- end-to-end 학습: 전체 앙상블을 하나의 통합된 시스템으로 최적화
- 확장성: 다양한 신경망 아키텍처(CNN, RNN, Transformer) 조합 가능
- 자동 특성 학습: 수동 특성 엔지니어링 없이 자동으로 유용한 표현 학습
단점
- 데이터 요구량: 효과적인 학습을 위해 대량의 데이터 필요
- 훈련 시간: 여러 신경망 훈련으로 인한 매우 긴 학습 시간
- 하이퍼파라미터: 각 신경망별 복잡한 하이퍼파라미터 튜닝 필요
- 해석성 부족: 블랙박스 특성으로 인한 설명 가능성 제한
- 과적합 위험: 높은 모델 복잡도로 인한 과적합 가능성
6. SHAP 기반 설명 가능한 앙상블

NCDG라는 스태킹 앙상블 모델이 제안되었으며, Naive Bayes, Categorical Boosting, Decision Tree를 베이스 학습기로, Gradient Boosting을 메타 학습기로 사용한다.
혁신점:
- SHAP 통합: 모델의 해석 가능성 제공
- 특성 중요도: 각 특성의 기여도 시각화
- 실용성: 의료진단 등 설명이 필요한 분야에 적용
장점
- 투명성: SHAP을 통한 모델 의사결정 과정의 명확한 해석
- 특성 중요도: 각 특성의 기여도를 정량적으로 측정 및 시각화
- 신뢰성: 의료진단 등 고신뢰 도메인에서 활용 가능
- 디버깅 용이: 모델의 예측 근거를 명확히 파악하여 문제점 진단 쉬움
단점
- 계산 비용: SHAP 값 계산으로 인한 추가적인 계산 오버헤드
- 복잡성: SHAP 분석을 위한 추가적인 전문 지식과 도구 필요
- 성능 트레이드오프: 해석 가능성을 위해 일부 성능 희생 가능
- 스케일 제한: 대규모 데이터나 모델에서 SHAP 계산 시간 부담
7. 계층적 앙상블 (Hierarchical Ensemble)
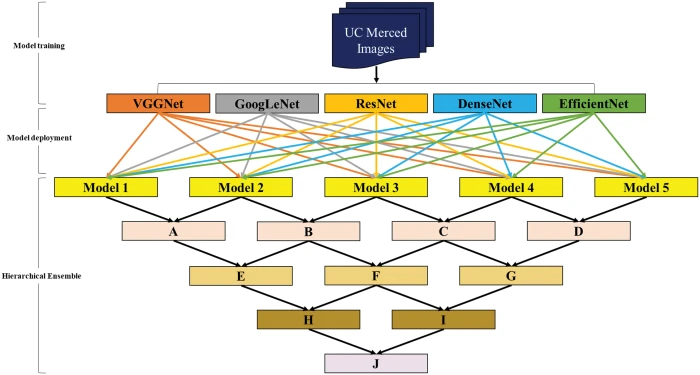
M1과 M2의 예측을 받아 M4에 입력하고, M2와 M3의 예측을 M5에 입력한 후, 최종적으로 M4와 M5를 결합하는 방식으로 베이스 모델 위에 두 레벨의 모델을 생성하는 유효한 스태킹 방법이다.
장점
- 유연한 구조: 복잡한 모델 조합과 연결 방식 설계 가능
- 특화 학습: 특정 모델 조합에 특화된 메타 모델 학습
- 확장성: 기존 앙상블에 새로운 레이어나 모델 추가 용이
- 모듈화: 각 계층을 독립적으로 최적화하고 관리 가능
단점
- 설계 복잡성: 최적의 계층 구조 설계가 매우 어려움
- 관리 부담: 여러 계층의 모델들을 동시에 관리해야 하는 복잡성
- 과적합 위험: 복잡한 구조로 인한 과적합 가능성 증가
- 검증 어려움: 각 계층의 기여도를 개별적으로 평가하기 어려움
최신 앙상블 기법의 장점
앙상블 방법은 개별 모델에 비해 높은 예측 정확도를 가지며, 데이터셋에 선형 및 비선형 유형의 데이터가 모두 있을 때 매우 유용하다. 다른 모델들을 결합하여 이런 유형의 데이터를 처리할 수 있고, 편향/분산을 줄일 수 있으며 대부분의 경우 모델이 과소적합/과적합되지 않는다.
구현 고려사항
- 계산 복잡도: 멀티레벨 스태킹은 데이터와 시간 비용이 많이 든다
- 과적합 방지: K-fold 교차검증 사용 필수
- 모델 다양성: 서로 다른 알고리즘 조합이 효과적
- 메타모델 선택: 보통 단순한 모델(Linear/Logistic Regression) 사용
결론: 2025년 최신 앙상블 기법들은 어텐션 메커니즘, 멀티레벨 구조, 설명 가능성(SHAP) 등을 통합하여 성능과 해석성을 동시에 향상시키는 방향으로 발전하고 있다.
선택 가이드라인
기법추천 상황비추천 상황
| 멀티레벨 스태킹 | 높은 성능이 최우선, 충분한 자원 | 실시간 예측, 제한된 자원 |
| 어텐션 기반 | 모델별 기여도 분석 필요 | 단순한 문제, 계산 자원 부족 |
| 블렌딩 | 빠른 프로토타이핑, 간단한 구현 | 최고 성능 필요, 데이터 충분 |
| 동적 가중치 | 데이터 분포가 복잡하고 다양함 | 일관된 예측 결과 필요 |
| 딥러닝 기반 | 대용량 데이터, 복잡한 패턴 | 작은 데이터, 해석성 중요 |
| SHAP 기반 | 의료/금융 등 설명 필요 분야 | 성능만 중요한 경우 |
| 계층적 | 복잡한 도메인 지식 활용 | 단순한 문제, 관리 자원 부족 |