[클러스터링] 클러스터링 알고리즘 정리
2025. 7. 1. 23:23ㆍ카테고리 없음
1. 분할 기반 클러스터링 (Partitioning-based)
K-means
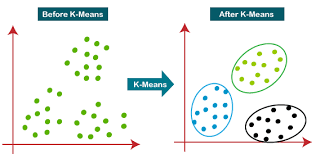
원리: 중심점 기반으로 클러스터를 형성 장점:
- 간단하고 빠름
- 구현이 쉬움
- 큰 데이터셋에 효율적
단점:
- K 값을 미리 정해야 함
- 구형 클러스터만 잘 찾음
- 초기값에 민감
- 이상치에 취약
사용 예시: 고객 세분화, 이미지 압축
K-medoids (PAM)
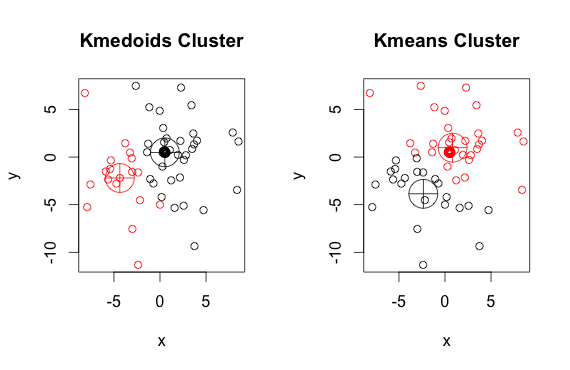
원리: 실제 데이터 포인트를 중심점으로 사용 장점:
- 이상치에 더 강건
- 임의 거리 척도 사용 가능
단점:
- K-means보다 느림
- 여전히 K를 미리 정해야 함
K-modes / K-prototypes
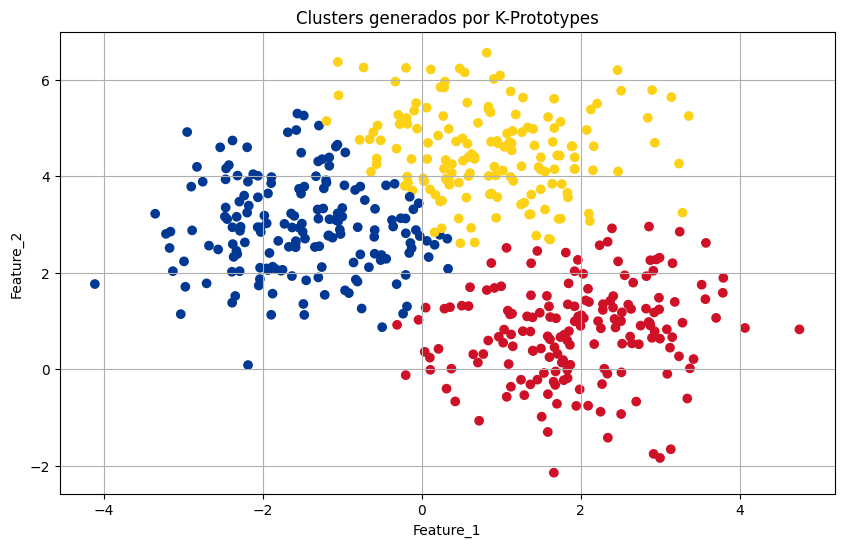
원리: 범주형 데이터용 K-means 변형 장점:
- 범주형 데이터 처리 가능
- 혼합 데이터 타입 지원
단점:
- 알고리즘이 복잡
- 모드 계산 비용
2. 계층적 클러스터링 (Hierarchical)
응집형 (Agglomerative)

원리: 개별 점에서 시작해 점진적으로 병합 연결 방법:
- Single Link: 최근접 거리
- Complete Link: 최원거리
- Average Link: 평균 거리
- Ward: 분산 최소화
장점:
- K를 미리 정하지 않아도 됨
- 덴드로그램으로 시각화 가능
- 임의 모양 클러스터 발견
단점:
- 시간복잡도 O(n³)
- 큰 데이터에 부적합
- 노이즈에 민감
분할형 (Divisive)
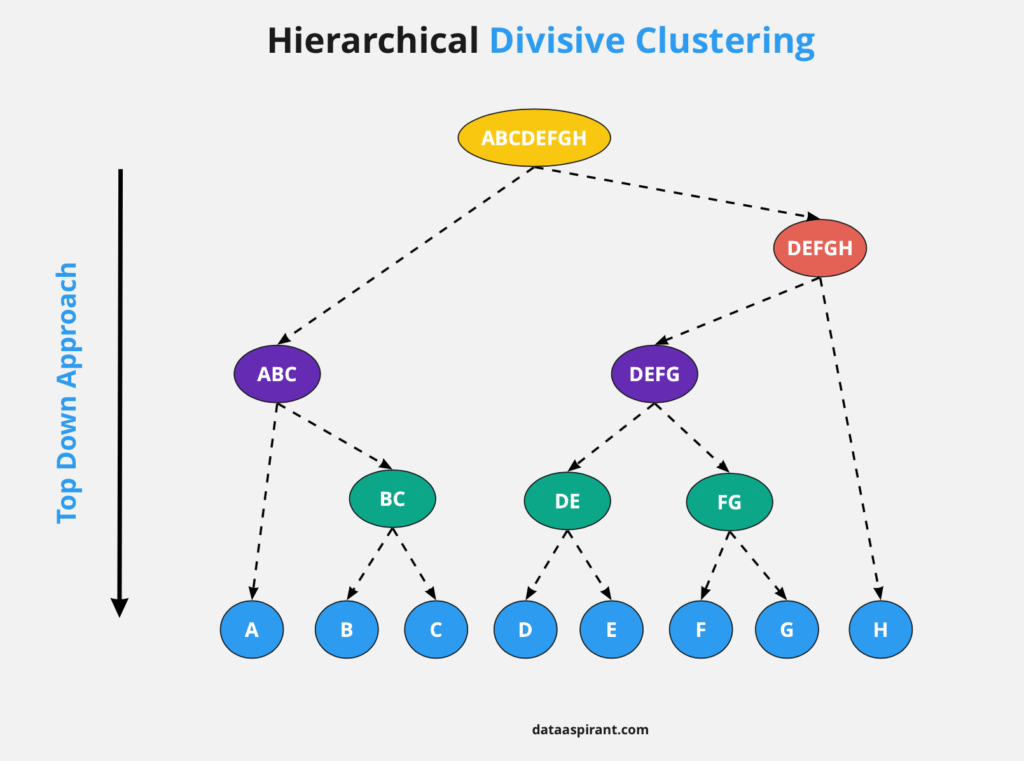
원리: 전체에서 시작해 점진적으로 분할
장점:
- 상위 레벨 구조 파악에 좋음
단점:
- 더 복잡하고 비용이 높음
- 잘 사용되지 않음
3. 밀도 기반 클러스터링 (Density-based)
DBSCAN

원리: 밀도가 높은 영역을 클러스터로 정의 매개변수:
- eps: 이웃 반경
- min_samples: 최소 점 개수
장점:
- 임의 모양 클러스터 발견
- 이상치 자동 탐지
- 클러스터 수 자동 결정
단점:
- 매개변수 선택 어려움
- 밀도가 다른 클러스터 처리 곤란
- 고차원에서 성능 저하
OPTICS

원리: DBSCAN의 확장, 다양한 밀도 처리
장점:
- 다양한 밀도의 클러스터 발견
- 클러스터 구조 시각화
단점:
- 더 복잡한 매개변수
- 해석이 어려움
HDBSCAN

원리: 계층적 DBSCAN
장점:
- 다양한 밀도 자동 처리
- 더 강건한 클러스터 탐지
단점:
- 계산 복잡도 높음
4. 격자 기반 클러스터링 (Grid-based)
STING

원리: 공간을 격자로 나누어 처리 장점:
- 빠른 처리 속도
- 큰 데이터셋 처리 가능
단점:
- 격자 크기에 민감
- 고차원에서 비효율
CLIQUE
원리: 부분공간에서 밀도 기반 클러스터링
장점:
- 고차원 데이터 처리
- 부분공간 클러스터 발견
단점:
- 매개변수 많음
- 해석 복잡
5. 모델 기반 클러스터링 (Model-based)
Gaussian Mixture Model (GMM)

원리: 가우시안 분포의 혼합으로 모델링 장점:
- 확률적 클러스터 할당
- 타원형 클러스터 처리
- 클러스터 확률 제공
단점:
- EM 알고리즘으로 느림
- 초기값에 민감
- 클러스터 수 선택 필요
Expectation-Maximization (EM)

원리: 우도 최대화를 통한 클러스터링 장점:
- 이론적 기반 탄탄
- 다양한 분포 가정 가능
단점:
- 수렴 보장 없음
- 지역 최적값 문제
6. 스펙트럴 클러스터링 (Spectral)

Normalized Cuts
원리: 그래프의 고유벡터를 이용한 클러스터링, kmeans 와 가장 큰 차이는 중심점의 유무
장점:
- 복잡한 모양 클러스터 발견
- 이론적으로 우수
단점:
- 계산 비용 높음
- 클러스터 수 사전 지정 필요
- 매개변수 선택 어려움
7. 퍼지 클러스터링 (Fuzzy)

Fuzzy C-means (FCM)
원리: 소프트 클러스터 할당
장점:
- 중간 영역 포인트 처리
- 불확실성 정량화
단점:
- 해석이 어려움
- 계산 복잡도 높음
8. 최신 딥러닝 기반
Deep Embedded Clustering (DEC)

원리: 오토인코더 + 클러스터링
장점:
- 고차원 데이터 처리
- 특성 학습과 클러스터링 동시
단점:
- 매우 복잡
- 대량 데이터 필요
Variational Deep Embedding (VaDE)

원리: VAE + GMM
장점:
- 생성 모델과 클러스터링 결합
단점:
- 학습이 어려움
알고리즘 선택 가이드
데이터 특성별
- 구형 클러스터: K-means
- 임의 모양: DBSCAN, Spectral
- 계층 구조: Hierarchical
- 다양한 밀도: HDBSCAN
- 고차원: Spectral, Deep learning
데이터 크기별
- 소규모 (<1K): Hierarchical
- 중간 규모 (1K-100K): K-means, DBSCAN
- 대규모 (>100K): Mini-batch K-means, BIRCH
요구사항별
- 빠른 속도: K-means
- 정확도 우선: Spectral, GMM
- 이상치 탐지: DBSCAN
- 확률 정보: GMM
- 해석 용이: K-means, Hierarchical