[컴퓨터 비전의 모든 것] Image Classification (3) : 모델 비교
2024. 12. 20. 02:25ㆍMOOC
Beyond ResNet
ResNet 이후 DenseNet, SENet, EfficientNet, Deformable Convolution 등이 등장하며 모델 구조가 더 발전되었다.
- DenseNet
DenseNet은 Residual block에서 skip connection을 사용하는 대신, 모든 이전 입력을 채널 축을 중심으로 concatenation하여 상위 레이어에서 하위 레이어의 특징을 모두 활용할 수 있도록 설계되었다. 이를 통해 더 복잡한 매핑을 학습하기 용이하지만, 파라미터 수가 증가하고 계산량이 많아지는 단점이 있다.
- SENet
SENet은 채널 간 관계를 모델링하여 중요한 특징에 높은 가중치를 부여하는 attention 메커니즘을 도입한 모델이다. Squeeze와 Excitation 과정을 통해 global average pooling으로 채널 간 attention을 계산하고 이를 기반으로 feature map을 조정한다.
- EfficientNet
EfficientNet은 width, depth, resolution scaling을 조합한 compound scaling 방식을 도입하여 네트워크의 효율성과 성능을 극대화한 모델이다. 동일한 FLOPS 대비 뛰어난 성능을 보여주는 것으로 평가된다.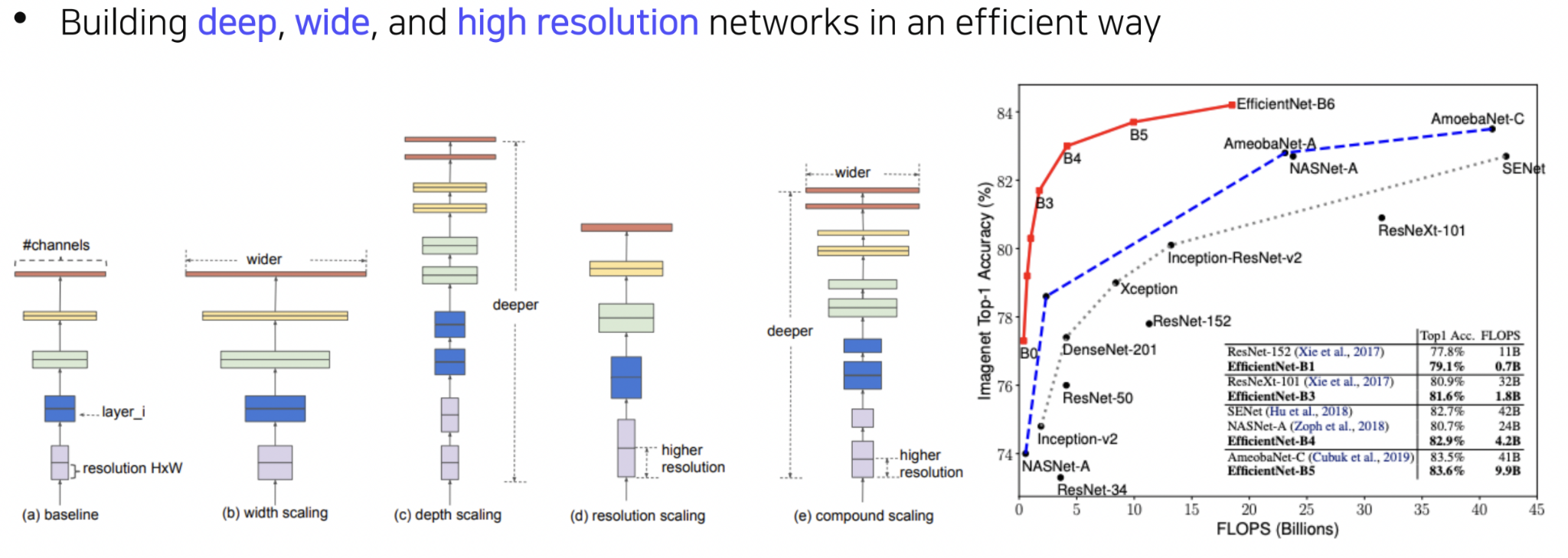
- Deformable Convolution
Deformable Convolution은 입력 feature map의 2D offset map을 기반으로 convolution 연산을 조정하여 변형 가능한 형태의 receptive field를 생성하는 방식이다. 이를 통해 정적인 convolution 방식으로는 어려운 자연스러운 움직임을 포착할 수 있다.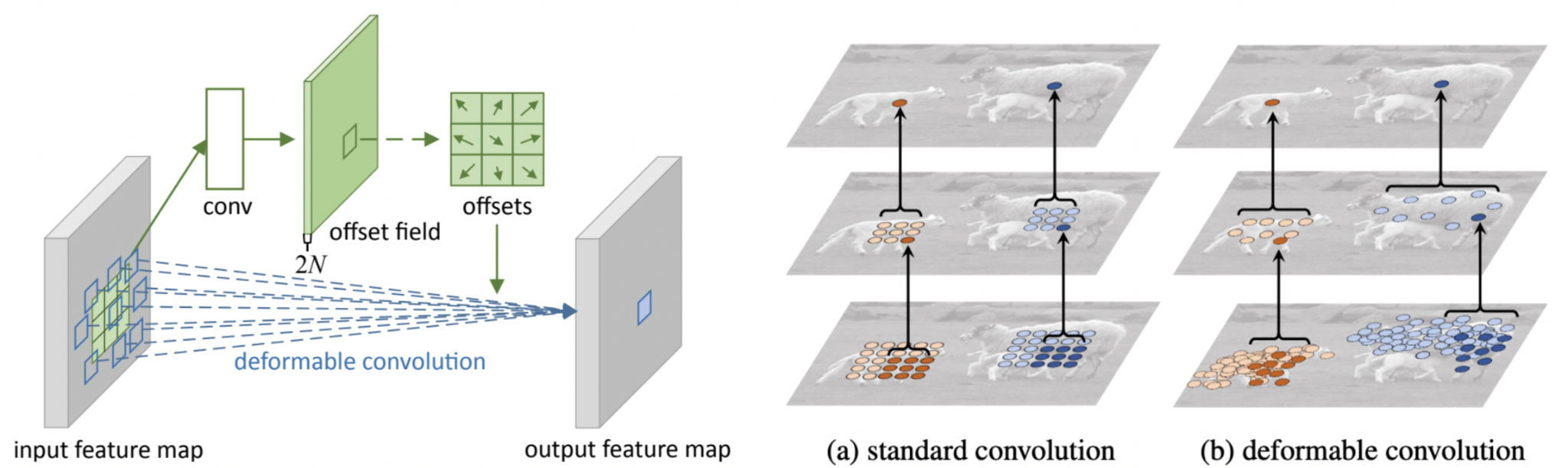
- Summary of Image Classification
AlexNet부터 EfficientNet까지 다양한 CNN 모델을 종합적으로 살펴보면, AlexNet은 단순한 구조로 계산이 간단하지만 성능이 낮고, VGGNet은 3x3 convolution 기반으로 설계되었으나 모델 사이즈와 계산량이 커 효율성이 낮다. Inception 계열 모델은 높은 성능과 효율성을 동시에 달성했지만 구현이 복잡하다. ResNet은 depth scaling으로 성능을 향상시켰지만 계산량이 많아 효율성이 떨어진다. EfficientNet은 compound scaling으로 높은 성능과 효율성을 동시에 제공하며 기존 모델을 뛰어넘었다.
- CNN Backbones
Inception 계열 모델은 효율성과 높은 성능을 보여주지만 구현이 난해한 부분이 있어, 일반적으로 VGGNet이나 ResNet이 다양한 작업에서 backbone으로 사용된다.
'MOOC' 카테고리의 다른 글
| [컴퓨터 비전의 모든 것] Object Detection (2) | 2024.12.20 |
|---|---|
| [컴퓨터 비전의 모든 것] Semantic Segmentation (0) | 2024.12.20 |
| [컴퓨터 비전의 모든 것] Image Classification (2) : 대표 모델 (0) | 2024.12.20 |
| [컴퓨터 비전의 모든것] Annotation Efficient Learning (0) | 2024.12.20 |
| [컴퓨터 비전의 모든 것] Data Augmentation (2) | 2024.12.20 |