2024. 12. 20. 02:52ㆍMOOC
Object Detection은 컴퓨터 비전 분야에서 중요한 과제로, 이미지 분류부터 시작하여 Semantic Segmentation, Instance Segmentation, Panoptic Segmentation 등의 고급 작업에 활용된다. 이 중에서 Object Detection 기술은 개체를 구분하고 장면을 이해하기 위한 근본적인 기술로 볼 수 있다.
Object Detection이란?
Object Detection은 분류(classification)와 bounding box를 동시에 예측하는 작업이다. 주어진 이미지에서 특정 물체의 위치를 bounding box 형태로 예측하고, 해당 물체의 클래스를 분류하는 것이 핵심이다.

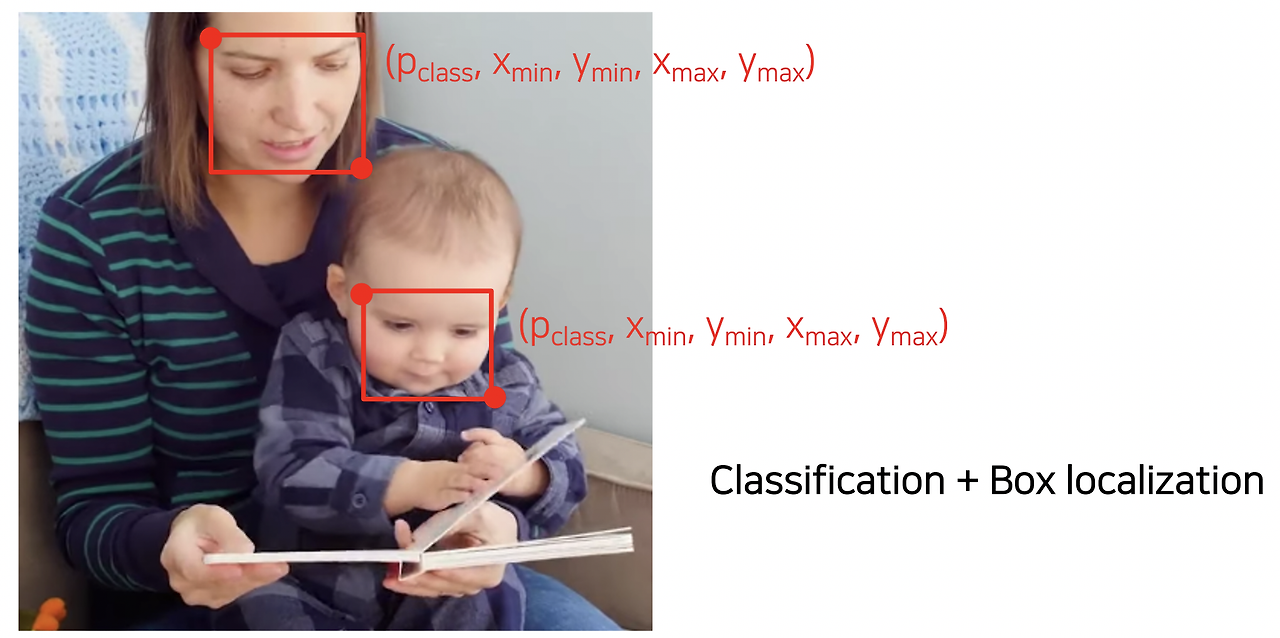
Object Detection의 응용
Object Detection은 다양한 산업 분야에서 활용된다. 대표적으로 자율주행 기술, OCR(광학 문자 인식) 등이 있으며, 이러한 활용 가능성 덕분에 산업적 가치가 매우 크다.
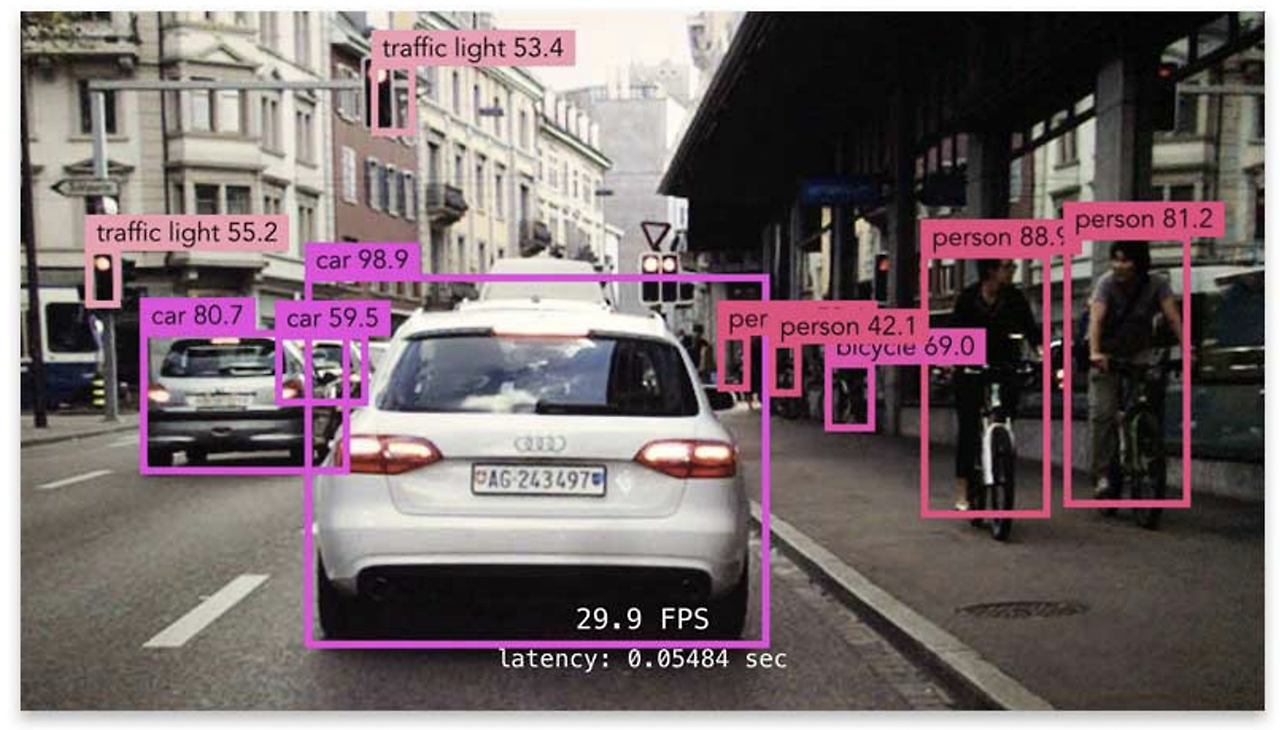
Two-stage Detector (R-CNN 계열)
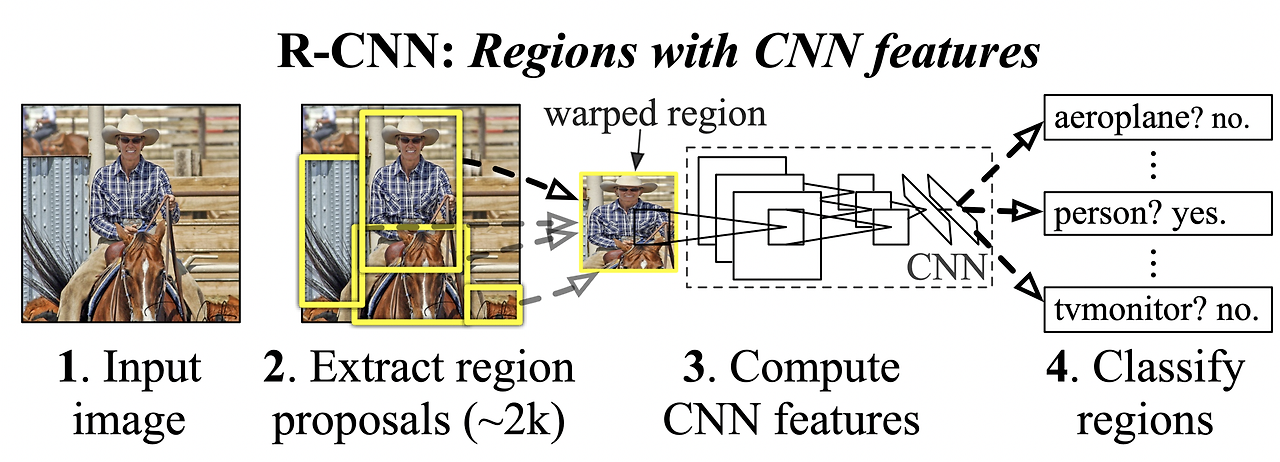
R-CNN
R-CNN은 딥러닝 기반 Object Detection의 초기 접근법으로, 간단한 프로세스를 갖는다. Selective Search 등 heuristic 방법으로 약 2000개의 region proposal을 구하고, 이를 적절한 크기로 변환(warping)하여 CNN을 통해 feature를 추출한다. 이후 SVM을 이용해 classification을 수행한다. 하지만 모든 region proposal마다 별도의 classification을 수행하므로 속도가 느리며, end-to-end 학습이 불가능한 한계가 있다.
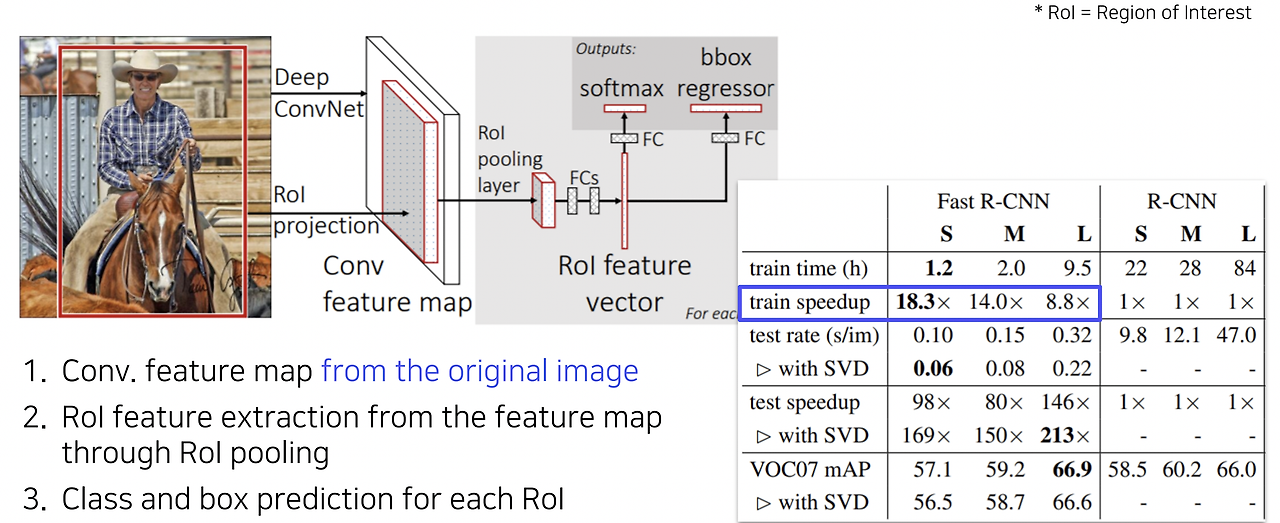
Fast R-CNN
R-CNN의 속도 문제를 해결하기 위해 Fast R-CNN이 제안되었다. 이 방법은 이미지 전체의 feature map을 한 번에 추출한 뒤, ROI(Region of Interest) Pooling 기법으로 필요한 영역만 추출하여 분류와 bounding box regression을 수행한다. R-CNN 대비 약 18배 빠르지만, 여전히 heuristic region proposal 방식의 한계가 있다.
Hypercolumns는 이미지를 분할하거나 물체를 인식할 때 픽셀 단위로 더 풍부한 정보를 사용하는 방법이다. FCN(Fully Convolutional Network)과 비슷한 구조를 가지지만, 낮은 레이어(세부 정보)와 높은 레이어(큰 그림 정보)를 더욱 정교하게 결합하며, Bounding Box(물체의 위치를 나타내는 네모)를 추가로 사용하는 점에서 차이가 있다
Faster R-CNN
Faster R-CNN은 region proposal 단계를 개선하여 최초로 end-to-end 구조를 도입했다. Region Proposal Network (RPN)을 사용해 neural network 기반으로 region proposal을 수행하며, Anchor Box를 활용해 bounding box를 예측한다. 이 과정에서 Non-Maximum Suppression(NMS) 기법으로 중복된 region을 제거한다.
Faster R-CNN은 물체 탐지(Object Detection) 분야에서 중요한 모델로, 물체의 위치(Bounding Box)와 클래스(예: 사람, 자동차)를 동시에 예측한다. Faster R-CNN의 핵심은 Region Proposal Network (RPN)을 사용하여 효율적이고 빠르게 물체 후보 영역(region proposal)을 생성하는 것이다. 이를 통해 이전 방식들보다 더 빠르고 정확한 탐지가 가능하다.
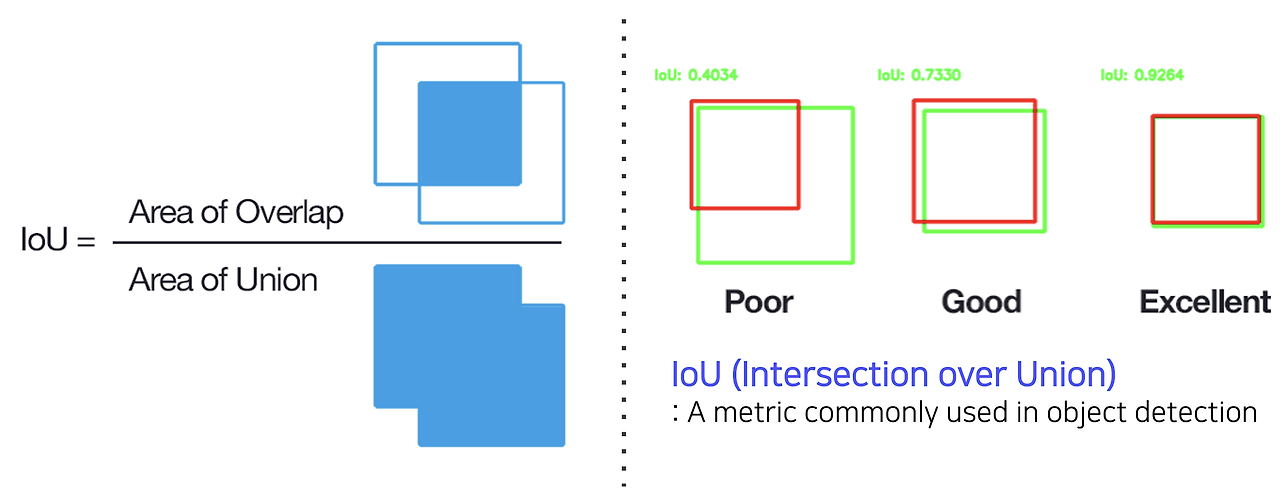
Single-stage Detector
YOLO
YOLO는 Single-stage Detector의 대표적인 예로, 입력 이미지를 SxS의 grid로 나누고 각 grid에서 bounding box 좌표, confidence score, classification score를 예측한다. 간단한 구조와 빠른 속도를 자랑하지만, localization 성능이 낮은 한계가 있다.

SSD (Single Shot MultiBox Detector)
SSD는 YOLO의 localization 문제를 개선하기 위해 multi-scale feature map을 활용한다. 여러 레이어에서 bounding box를 출력하여 다양한 크기의 물체를 탐지할 수 있도록 설계되었다. 이를 통해 YOLO보다 더 높은 성능과 빠른 속도를 동시에 제공한다.
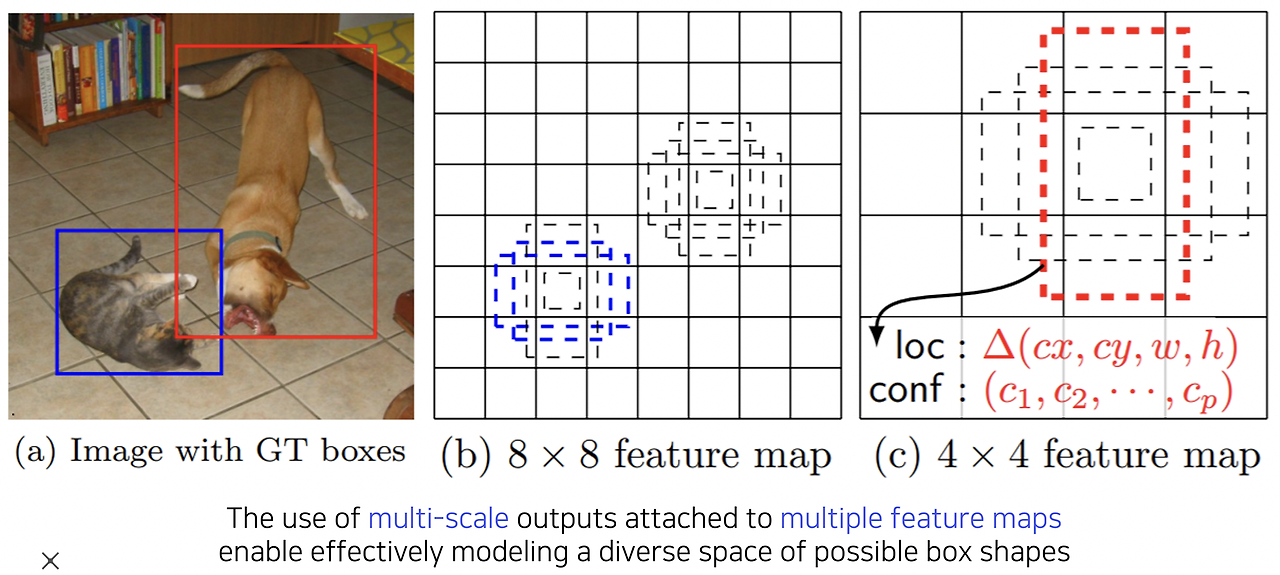
Single-stage vs Two-stage Detector
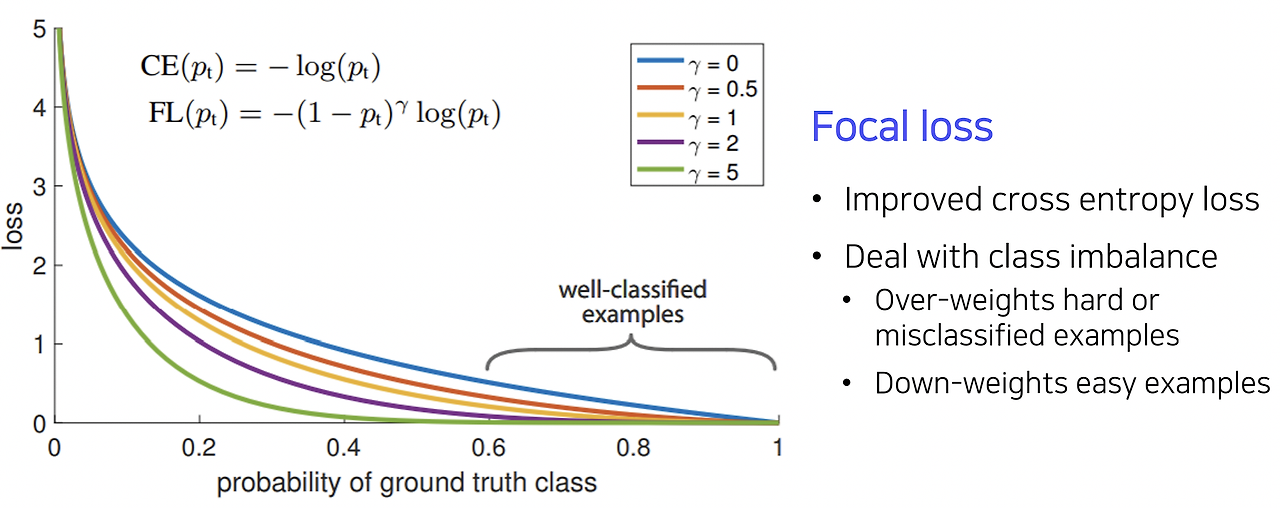
Focal Loss
Single-stage Detector는 ROI Pooling이 없기 때문에 모든 영역에서 loss가 계산된다. 이는 class imbalance 문제로 이어지며, 이를 해결하기 위해 Focal Loss가 제안되었다. Focal Loss는 모델이 잘 예측하지 못하는 클래스에 더 큰 loss를 부여하여 불균형 문제를 완화한다.
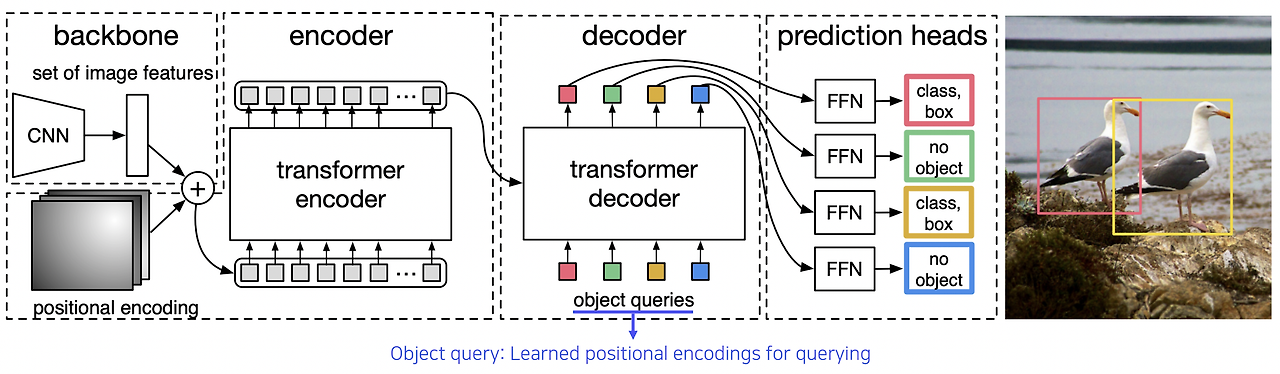
RetinaNet
RetinaNet은 FPN(Feature Pyramid Network)을 도입하여 multi-scale object를 효율적으로 탐지하는 구조다. SSD와 유사한 속도를 유지하면서도 높은 성능을 보여준다.

최신 연구: DETR
DETR은 Transformer를 활용한 Object Detection 기법이다. CNN으로 추출한 특징을 positional encoding과 결합하여 Transformer Encoder에 입력하고, Decoder에서 object query를 활용해 물체와 bounding box를 예측한다. 이 방법은 기존 방식과 차별화된 접근으로 주목받고 있다.
'MOOC' 카테고리의 다른 글
| [컴퓨터 비전의 모든 것] CNN Visualization (2) : 시각화 방법 (3) | 2024.12.20 |
|---|---|
| [컴퓨터 비전의 모든 것] CNN Visualization (1) : 동작 원리 (2) | 2024.12.20 |
| [컴퓨터 비전의 모든 것] Semantic Segmentation (0) | 2024.12.20 |
| [컴퓨터 비전의 모든 것] Image Classification (3) : 모델 비교 (0) | 2024.12.20 |
| [컴퓨터 비전의 모든 것] Image Classification (2) : 대표 모델 (0) | 2024.12.20 |