2024. 4. 9. 03:58ㆍMOOC
Convolution Nueral Network 실습-1
- Dataset: CIFAR 10
- 학습 내용:
- 데이터 로딩 및 전처리
- Tensorflow 모델 생성 방법
- Convolutional Layer 생성 실습
1. 데이터 로딩 및 전처리
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
#CIFAR-10 데이터 세트를 로드
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
(train_images,train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
(train_images,train_labels),(test_images,test_labels) = datasets.cifar10.load.data()
# 이미지 데이터의 픽셀 값을 0과 1 사이로 정규화한다. 컴퓨터에서 이미지의 픽셀 값은 보통 0부터 255 사이의 정수로 표현되는데,
# 이를 255로 나누어 신경망 입력으로 사용하기 좋은 형태(0과 1 사이의 실수)로 만든다.
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images,test_images=train_images/255.0, test_images/255.0
train_images,test_images=train_images/255.0, test_images/255.0Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 6s 0us/step
-> 데이터를 로드하고 전처리
#CIFAR-10 데이터셋에 포함된 10개 클래스의 이름을 문자열 리스트로 정의
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
#matplotlib을 사용하여 시각화할 그림의 크기를 가로 10인치, 세로 10인치로 설정
plt.figure(figsize=(10,10))
#0부터 24까지의 숫자(총 25개)에 대해 반복문을 실행하여 처음 25개의 이미지를 시각화
for i in range(25):
#5x5의 그리드에서 (i+1)번째 위치에 서브플롯을 생성
plt.subplot(5,5,i+1)
plt.subplot(5,5,i+1)
#서브플롯의 x축과 y축의 틱(눈금)을 제거
plt.xticks([])
plt.yticks([])
#서브플롯에 그리드를 표시하지 않도록 설정
plt.grid(False)
plt.grid(False)
plt.grid(False)
#train_images에서 i번째 이미지를 흑백 컬러맵(plt.cm.binary)으로 시각화
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.imshow(train_images[i],cmap=plt.cm.binary)
plt.imshow(train_images[i],cmap=plt.cm.binary)
#train_labels[i][0]는 i번째 이미지의 라벨 인덱스를 참조하고, class_names[인덱스]는 그 인덱스에 해당하는 클래스 이름을 반환
plt.xlabel(class_names[train_labels[i][0]])
plt.show()
-> CIFAR-10 데이터셋의 처음 25개 이미지를 5x5 그리드로 시각화하여 각 이미지의 실제 라벨(예: 'airplane', 'automobile' 등)과 함께 표시하는 과정
2. 인공지능 모델을 만드는 3가지 방법
(1) Functional API 활용
import tensorflow as tf
inputs = tf.keras.Input(shape=(32, 32, 3)) # 32x32x3 (RGB)
x = tf.keras.layers.Flatten(inputs) # Flatten layer
x = tf.keras.layers.Dense(4, activation=tf.nn.relu)(x)
outputs = tf.keras.layers.Dense(10, activation=tf.nn.softmax)(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)(2) Model class 상속
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax)
def call(self, inputs):
x = self.dense1(inputs)
return self.dense2(x)
model = MyModel()(3) Sequential Fuction 활용
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(8, input_shape=(16,)))
model.add(tf.keras.layers.Dense(4))3. Convolution Layer 생성 실습
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid',
data_format=None, dilation_rate=(1, 1), groups=1, activation=None,
use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None, **kwargs
)(1) Functional API 활용
Model 생성
#모델의 입력을 정의한다. 입력의 형태는 (32, 32, 3)으로, 이는 32x32 크기의 RGB 이미지를 나타낸다. 여기서 3은 채널 수(RGB)를 의미한다
inputs = tf.keras.Input(shape=(32, 32, 3))
inputs= tf.keras.Input(shape=(32,32,3))
inputs=tf.keras.Input(shape=(32,32,3))
inputs=tf.kras.Input(shape=(32,32,3))
#첫 번째 합성곱 층(Convolutional Layer)을 정의하고 입력에 적용한다.
#이 층은 32개의 필터를 사용하며, 각 필터의 크기는 3x3이다. 스트라이드는 (1, 1)이고, 패딩은 'valid'로 설정되어있다. 활성화 함수로는 'relu'가 사용된다
x = tf.keras.layers.Conv2D(filters=32,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')(inputs)
x= tf.keras.layers.Conv2D(filter=32,
kernal_size=(3,3),
strides=(1,1),
padding='valid',
activation='relu')(inputs)
#두 번째 합성곱 층을 추가한다. 이번에는 64개의 필터를 사용하고, 나머지 파라미터는 첫 번째 합성곱 층과 유사하다
x = tf.keras.layers.Conv2D(filters=64,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')(x)
#합성곱 층에서 나온 특성 맵을 1차원 배열로 평탄화한다. 이는 다음에 올 완전 연결 층(Dense Layer)의 입력으로 사용된다
x = tf.keras.layers.Flatten()(x)
#평탄화된 특성에 대해 완전 연결 층을 적용하고, 10개의 출력 노드를 가진다. 각 노드는 CIFAR-10 데이터셋의 클래스 하나에 해당한다.
#활성화 함수로는 softmax를 사용하여, 10개 클래스에 대한 예측 확률 분포를 출력한다
outputs = tf.keras.layers.Dense(10, activation=tf.nn.softmax)(x)
#입력과 출력을 사용하여 모델을 정의한다. 이 모델은 위에서 정의한 층을 포함하며, model_by_func라는 이름으로 저장된다
model_by_func = tf.keras.Model(inputs=inputs, outputs=outputs, name="model_by_func")-> TensorFlow의 함수형 API를 활용하여 구조화되고 확장 가능한 방식으로 CNN 모델을 정의하는 예시를 보여준다. 함수형 API를 사용하면 다중 입력, 다중 출력, 모델 내 모델 등 복잡한 모델 구조를 쉽게 만들 수 있다
모델 Compile: Optimizer, loss, metrics 모두 여기서 선언
#optimizer='adam': 최적화 알고리즘으로 Adam을 사용한다. Adam 최적화 알고리즘은 학습률을 자동으로 조정하면서 가중치를 업데이트한다
#손실 함수로 Sparse Categorical Crossentropy를 사용한다. from_logits=True는 모델 출력이 로짓(소프트맥스 함수를 적용하기 전의 원시 출력 값)임을 나타낸다.
# 이 손실 함수는 다중 클래스 분류 문제에 적합하며, 각 샘플에 대해 단 하나의 정답 라벨이 있을 때 사용된다
#모델의 성능을 평가하는 데 사용할 메트릭으로 정확도(accuracy)를 선택한다.
model_by_func.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model_by_func.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model_by_func.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropyi(from_logits=True),
metrics=['accurarcy'])
model_by_func.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])Model 요약
model_by_func.summary()Model: "model_by_func"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
_________________________________________________________________
flatten (Flatten) (None, 50176) 0
_________________________________________________________________
dense (Dense) (None, 10) 501770
=================================================================
Total params: 521,162
Trainable params: 521,162
Non-trainable params: 0
_________________________________________________________________Model: "model_by_func": 모델의 이름이 "model_by_func"이다. 이 이름은 모델을 생성할 때 지정한 것이다.
input_1 (InputLayer): 모델의 입력 층이다. 입력 데이터의 형태는 (None, 32, 32, 3)이다. 여기서 None은 배치 크기를 나타내며, 이는 어떤 크기의 데이터도 받을 수 있음을 의미한다. 32, 32, 3은 각각 이미지의 높이, 너비, 채널 수를 나타낸다.
conv2d (Conv2D): 첫 번째 합성곱 층이다. 출력 형태는 (None, 30, 30, 32)로, 첫 번째 차원은 여전히 배치 크기를 나타내며, 30, 30은 필터 적용 후 이미지의 크기가 조금 줄어든 것을 의미하고, 32는 이 층에서 생성된 필터(또는 특징 맵)의 수다. 이 층은 896개의 파라미터를 가지고 있다.
conv2d_1 (Conv2D): 두 번째 합성곱 층이다. 출력 형태는 (None, 28, 28, 64)이며, 이는 두 번째 합성곱 층을 통과한 후 이미지 크기가 다시 줄어들고, 필터의 수가 64개로 증가했음을 나타낸다. 이 층은 18,496개의 파라미터를 가지고 있다.
flatten (Flatten): 평탄화 층이다. 이 층은 이전 층의 출력을 1차원 배열로 변환한다. 여기서 출력 형태는 (None, 50176)으로, 28x28x64에서 나온 50,176개의 특징들이 일렬로 늘어선 것을 나타낸다. 이 층은 학습할 파라미터가 없다.
dense (Dense): 완전 연결 층(또는 밀집 층)이다. 출력 형태는 (None, 10)으로, 모델이 최종적으로 10개의 다른 클래스 중 하나로 분류할 수 있음을 나타낸다. 이 층은 501,770개의 파라미터를 가지고 있다. Total params: 521,162: 모델 전체의 학습 가능한 파라미터 수는 521,162개다.
Trainable params: 521,162: 모든 파라미터가 학습 가능하다.
Non-trainable params: 0: 학습 불가능한 파라미터는 없다.
학습
epochs, validation data set 등 설정
#훈련 데이터에 대해 학습을 진행
history = model_by_func.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))Epoch 1/10
1563/1563 [==============================] - 38s 5ms/step - loss: 2.1257 - accuracy: 0.3260 - val_loss: 2.0112 - val_accuracy: 0.4450
Epoch 2/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.9582 - accuracy: 0.4988 - val_loss: 1.9512 - val_accuracy: 0.5064
Epoch 3/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8952 - accuracy: 0.5642 - val_loss: 1.9059 - val_accuracy: 0.5528
Epoch 4/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8622 - accuracy: 0.5964 - val_loss: 1.8956 - val_accuracy: 0.5616
Epoch 5/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8280 - accuracy: 0.6319 - val_loss: 1.8828 - val_accuracy: 0.5757
Epoch 6/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8000 - accuracy: 0.6593 - val_loss: 1.8614 - val_accuracy: 0.5977
Epoch 7/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7770 - accuracy: 0.6835 - val_loss: 1.8546 - val_accuracy: 0.6057
Epoch 8/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7640 - accuracy: 0.6970 - val_loss: 1.8407 - val_accuracy: 0.6193
Epoch 9/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7514 - accuracy: 0.7092 - val_loss: 1.8522 - val_accuracy: 0.6054
Epoch 10/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7373 - accuracy: 0.7241 - val_loss: 1.8418 - val_accuracy: 0.6156-> 훈련 데이터에 대해 학습을 진행하고, 각 에폭마다의 훈련 손실(training loss), 훈련 정확도(training accuracy), 검증 손실(validation loss), 검증 정확도(validation accuracy)를 기록
평가(Evaluation)
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
#테스트 데이터셋(test_images, test_labels)에 대해 평가
test_loss, test_acc = model_by_func.evaluate(test_images, test_labels, verbose=2)313/313 - 1s - loss: 1.8418 - accuracy: 0.6156
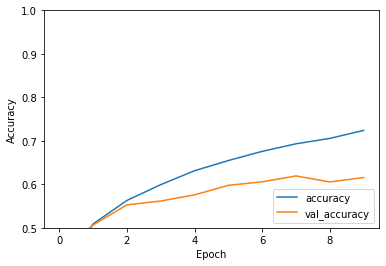
-> 테스트 데이터셋 평가 및 시각화
학습 정확도는 계속해서 증가하는 경향을 보이고 있다. 이는 모델이 훈련 데이터에 점점 더 잘 적응하고 있음을 의미한다.
검증 정확도도 증가하고 있지만, 학습 정확도에 비해 낮은 경향을 보인다. 이는 모델이 훈련 데이터에 비해 검증 데이터에서는 다소 낮은 성능을 보이고 있음을 나타낸다.
에폭이 증가함에 따라 학습 정확도와 검증 정확도 사이의 간격이 조금씩 벌어지는 것처럼 보인다. 이는 과적합의 가능성을 시사한다. 즉, 모델이 훈련 데이터에는 잘 맞지만, 일반화(generalize) 성능은 상대적으로 떨어질 수 있다는 의미다.
그래프의 y축 범위가 0.5에서 1.0으로 설정되어 있어, 모델의 정확도가 상당히 높은 것을 알 수 있다. 일반적으로, 이 범위의 정확도는 이미지 분류 작업에서 좋은 성능을 나타낸다고 볼 수 있다.
(2) Model class 상속
#tf.keras.Model을 상속받는 새로운 클래스 ModelByClass를 정의
class ModelByClass(tf.keras.Model):
class ModelByClass(tf.keras.Model):
#클래스의 생성자를 정의
def __init__(self):
#ModelByClass의 부모 클래스인 tf.keras.Model의 생성자를 호출하여 초기화
super(ModelByClass, self).__init__()
super(ModelByClass, self).__init__()
super(ModelByClass, self).__init__()
#첫 번째 합성곱 층을 모델의 속성으로 정의하고 초기화 , 이 층은 32개의 필터를 가지며, 3x3 크기의 커널을 사용
self.conv2d_1 = tf.keras.layers.Conv2D(filters=32,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')
self.conv2d_1= tf.keras.layers.Conv2D(filters=32,
kernel_size=(3,3),
strides=(1,1),
padding='valid',
activation='relu')
#두 번째 합성곱 층을 모델의 속성으로 정의하고 초기화한다. 이 층은 64개의 필터를 가지며, 역시 3x3 크기의 커널을 사용
self.conv2d_2 = tf.keras.layers.Conv2D(filters=64,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')
#Flatten 층을 정의하여, 이전 층의 출력을 1차원 배열로 평탄화한다. 이는 합성곱 층의 출력을 완전 연결 층에 연결하기 위한 준비 단계다
self.flatten = tf.keras.layers.Flatten()
self.flatten = tf.keras.layers.Flatten()
self.flatten=tf.keras.layers.Flatten()
self.flatten= tf.keras.layers.Flatten()
#마지막 완전 연결 층인 Dense 층을 정의한다. 이 층은 10개의 출력을 가지며, softmax 활성화 함수를 사용하여 다중 클래스 분류를 수행한다
self.dense = tf.keras.layers.Dense(10, activation=tf.nn.softmax)
self.dense=tf.keras.layers.Dense(10, activation=tf.nn.softmax)
self.dense=tf.keras.layer.Dense(10, activation=tf.nn.softmax)
#모델의 포워드 패스를 정의하는 call 메소드다. 입력 데이터가 모델을 통해 어떻게 전파될지를 지정한다
def call(self, inputs):
#inputs를 첫 번째 합성곱 층에 전달하고, 그 출력을 두 번째 합성곱 층에 전달하며, 그 결과를 평탄화한다
x = self.conv2d_1(inputs)
x = self.conv2d_2(x)
x = self.flatten(x)
#평탄화된 출력을 Dense 층에 전달하고, 최종 출력을 반환한다
return self.dense(x)
#ModelByClass 클래스의 인스턴스를 생성한다. 이 인스턴스가 바로 모델 객체다
model_by_class = ModelByClass()
#모델을 컴파일한다. 이 과정에서 최적화 알고리즘으로 'adam'을 사용하며, 손실 함수로 'SparseCategoricalCrossentropy'를 지정한다.
#from_logits=True는 모델의 출력이 로짓(즉, 소프트맥스 함수를 적용하기 전의 값)임을 나타낸다. 또한, 성능 메트릭으로 'accuracy'를 사용한다.
model_by_class.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])-> TensorFlow의 서브클래싱 API를 사용하여 커스텀 CNN 모델 클래스를 정의하고 인스턴스화
앞선 모델 생성 단계에서 함수형 API를 통해 tf.keras.Input을 사용하여 입력 텐서를 정의하고, 이를 통해 데이터의 형태를 설정 하는 과정을 가졌지만,
함수형 API는 더 선언적이고, 연결된 층들 간의 관계가 명시적이다. 이 방법은 빠르고 직관적인 모델 프로토타이핑에 유리하며, 모델의 구조를 시각화하거나 분석하기 쉽다는 장점이 있다.
반면, 서브클래싱 API는 모델에 커스텀 동작을 추가할 때 더 유연성을 제공하고, 복잡한 모델을 생성할 때 필요한 더 세밀한 제어를 가능하게 한다. 그러나 이 방법은 모델의 구조를 빠르게 파악하거나 디버깅하기가 함수형 API보다는 어려울 수 있다
이런 차이점을 통해 서로 다른 모델링을 진행한다
학습
history = model_by_class.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))Epoch 1/10
1563/1563 [==============================] - 7s 4ms/step - loss: 2.1052 - accuracy: 0.3482 - val_loss: 1.9573 - val_accuracy: 0.5002
Epoch 2/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.9398 - accuracy: 0.5171 - val_loss: 1.9344 - val_accuracy: 0.5222
Epoch 3/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8880 - accuracy: 0.5705 - val_loss: 1.8933 - val_accuracy: 0.5647
Epoch 4/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8483 - accuracy: 0.6106 - val_loss: 1.8761 - val_accuracy: 0.5833
Epoch 5/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8175 - accuracy: 0.6418 - val_loss: 1.8729 - val_accuracy: 0.5843
Epoch 6/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7998 - accuracy: 0.6598 - val_loss: 1.8779 - val_accuracy: 0.5807
Epoch 7/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7832 - accuracy: 0.6766 - val_loss: 1.8522 - val_accuracy: 0.6070
Epoch 8/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7618 - accuracy: 0.6985 - val_loss: 1.8457 - val_accuracy: 0.6132
Epoch 9/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7509 - accuracy: 0.7097 - val_loss: 1.8519 - val_accuracy: 0.6064
Epoch 10/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7363 - accuracy: 0.7236 - val_loss: 1.8361 - val_accuracy: 0.6226
-> model_by_class 모델을 사용하여 주어진 훈련 데이터셋으로 모델을 학습시키고, 설정된 에폭 수만큼 반복하여 모델의 가중치를 조정 , 동시에, 검증 데이터셋을 사용하여 각 에폭 후 모델의 성능을 평가하고, 이 과정에서 얻은 정보를 history 객체에 저장
평가
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model_by_class.evaluate(test_images, test_labels, verbose=2)313/313 - 1s - loss: 1.8361 - accuracy: 0.6226
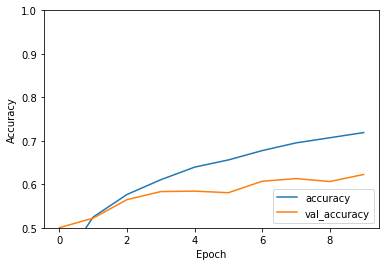
-> 평가 및 시각화 단계
그래프를 보면 정확도가 시간이 지남에 따라 지속적으로 증가하고 있음을 볼 수 있다.
훈련 정확도와 비교하여 검증 정확도가 낮고, 훈련 과정이 진행됨에 따라 두 선 사이의 간격이 점점 넓어지고 있다. 이는 과적합(overfitting)을 나타낼 수 있는 신호이다
전 모델링과 비교하면 정확도 차이가 줄어든것을 볼수가있다.
(3) Using Sequential
#Sequential 모델 인스턴스를 생성
model_by_seq = models.Sequential()
#모델에 첫 번째 합성곱 층(Conv2D)을 추가한다. 이 층은 32개의 필터를 가지고, 커널 사이즈는 3x3이며, 활성화 함수로 ReLU를 사용한다.
#input_shape=(32, 32, 3)은 모델이 기대하는 입력 데이터의 형태를 설정한다
model_by_seq.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
#두 번째 합성곱 층을 추가합니다. 이번에는 64개의 필터를 사용
model_by_seq.add(layers.Conv2D(64, (3, 3), activation='relu'))
#합성곱 층의 출력을 평탄화
model_by_seq.add(layers.Flatten())
#완전 연결 층(Dense)을 추가. 이 층은 10개의 뉴런(출력)을 가지며, 분류 문제에 대한 예측 확률을 출력하기 위해 softmax 활성화 함수를 사용
model_by_seq.add(layers.Dense(10, activation=tf.nn.softmax))
#모델을 컴파일
model_by_seq.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])-> 순차 모델(Sequential model)을 구성하고 컴파일하는 과정
model_by_seq.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
conv2d_5 (Conv2D) (None, 28, 28, 64) 18496
_________________________________________________________________
flatten_2 (Flatten) (None, 50176) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 501770
=================================================================
Total params: 521,162
Trainable params: 521,162
Non-trainable params: 0
_________________________________________________________________학습
history = model_by_seq.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))Epoch 1/10
1563/1563 [==============================] - 7s 4ms/step - loss: 2.1005 - accuracy: 0.3532 - val_loss: 1.9868 - val_accuracy: 0.4713
Epoch 2/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.9292 - accuracy: 0.5295 - val_loss: 1.9070 - val_accuracy: 0.5524
Epoch 3/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8702 - accuracy: 0.5897 - val_loss: 1.8891 - val_accuracy: 0.5709
Epoch 4/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8394 - accuracy: 0.6206 - val_loss: 1.8696 - val_accuracy: 0.5883
Epoch 5/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.8022 - accuracy: 0.6583 - val_loss: 1.8595 - val_accuracy: 0.5996
Epoch 6/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7841 - accuracy: 0.6763 - val_loss: 1.8526 - val_accuracy: 0.6052
Epoch 7/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7641 - accuracy: 0.6961 - val_loss: 1.8361 - val_accuracy: 0.6215
Epoch 8/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7448 - accuracy: 0.7166 - val_loss: 1.8325 - val_accuracy: 0.6285
Epoch 9/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7385 - accuracy: 0.7218 - val_loss: 1.8403 - val_accuracy: 0.6178
Epoch 10/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.7234 - accuracy: 0.7370 - val_loss: 1.8335 - val_accuracy: 0.6257
평가
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model_by_seq.evaluate(test_images, test_labels, verbose=2)313/313 - 1s - loss: 1.8335 - accuracy: 0.6257

-> 평가 및 시각화
총 3개의 평가중에서 2번째 코드블록 평가인 모델 상속하고 구성하는 방법에 비해 이 모델은 성능이 약간 떨어지는것을 볼수있다.
'MOOC' 카테고리의 다른 글
| [Deep Learning 7] Convolution Nueral Network 실습-4 (0) | 2024.04.12 |
|---|---|
| [Deep Learning 5] 파이썬을_활용한_딥러닝_이론_및_실습_중급편_CNN_실습_2 (0) | 2024.04.11 |
| [Deep Learning 3] 3-1 최초의 인공지능 Perceptron (1) | 2024.04.07 |
| [Deep Learning 2] Chapter02_PyTorch_Background Coding (0) | 2024.04.07 |
| [Deep Learning 1] PyTorch Background (0) | 2024.04.04 |