2024. 4. 12. 17:29ㆍMOOC
Convolution Nueral Network 실습-4
- Dataset: CIFAR 10
- 학습 내용:
- 데이터 로딩 및 전처리
- ResNet-18
- ResNet-18 실습
1. 데이터 로딩 및 전처리
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 훈련 데이터(train_images, train_labels)와 테스트 데이터(test_images, test_labels)로 분할
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 이미지 데이터는 일반적으로 0부터 255 사이의 픽셀 값
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 4s 0us/step-> CIFAR-10 데이터셋을 로드하고 0.0과 1.0 사이의 값으로 정규화
train_images / 255.0, test_images / 255.0 : 이미지 데이터는 일반적으로 0부터 255 사이의 픽셀 값 을 가지기 때문에 255로 나누어 정규화를 한다
Verify Data
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()
ResNet18
- Network가 깊어질수록, 학습이 잘 이뤄지지 않는 문제점을 해결하고자 등장
- Network가 깊어짐으로서 발생하는 손실을 원래 정보를 더해줌으로써 해결
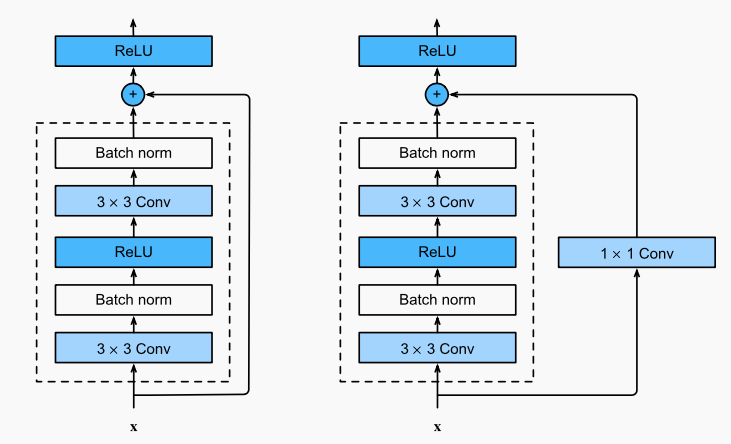
왼쪽 블록:
이것은 기본적인 ResNet 블록이다. 입력 x는 두 개의 컨볼루션 레이어와 배치 정규화, ReLU 활성화 함수를 거친다.
첫 번째 컨볼루션 레이어 다음과 두 번째 컨볼루션 레이어 전에 배치 정규화와 ReLU 활성화 함수가 적용된다.
그 후 최종 ReLU 활성화 함수 전에 입력 x와 두 번째 컨볼루션 레이어의 출력이 더해지는데, 이는 잔차 연결(또는 스킵 연결)이라고 부른다. 잔차 연결은 깊은 네트워크에서 기울기가 효과적으로 흐르도록 도와준다.
오른쪽 블록:
오른쪽 블록은 차원을 조정하는 1x1 컨볼루션 레이어를 포함하는 확장된 ResNet 블록이다.
기본 블록과 비슷하게, 두 개의 3x3 컨볼루션 레이어가 존재하며 배치 정규화와 ReLU 활성화가 적용된다.
차이점은, 입력 x가 직접 더해지기 전에 1x1 컨볼루션을 통과한다는 것이다. 이 추가 레이어는 입력의 차원을 변경하여, 블록의 출력과 더할 수 있게 만들어준다. 이것은 때때로 입력의 차원을 늘리거나 줄여야 할 때 사용된다.
*배치 정규화는 네트워크의 각 미니배치에 대해 레이어의 입력을 평균 0, 분산 1로 정규화
*미니배치(Mini-batch)는 기계학습에서 데이터셋을 더 작은 단위로 나눈 것

ResNet 구조는 심층 신경망(deep neural networks)의 훈련을 향상시키기 위해 개발된 아키텍처이다.
이 구조의 핵심 아이디어는 잔차 연결(residual connections) 또는 스킵 연결(skip connections)이다.이 연결은 레이어의 입력을 그 레이어의 출력에 직접 더함으로써, 입력이 네트워크의 더 깊은 레이어로 효율적으로 전파될 수 있도록 한다
기본적으로 ResNet은 여러 개의 레이어를 가진 블록을 포함하고 있는데, 이 블록들은 일반적으로 컨볼루션 레이어, 배치 정규화 레이어, 그리고 ReLU 활성화 함수로 구성되어 있다
레이어들 사이의 스킵 연결은 신호가 네트워크를 직접 통과할 수 있도록 해서, 깊은 네트워크에서 흔히 발생하는 소실된 기울기(vanishing gradient) 문제를 완화한다
3. ResNet18 Model 생성
8개의 레이어를 가진 모델
(1) Residual block 함수 정의
#add_residual_block 함수는 입력(inputs), 블록 번호(block_number), 입력 채널 수(in_channels), 출력 채널 수(out_channels)를 매개변수로 받는다
def add_residual_block(inputs, block_number, in_channels, out_channels):
_ = str(block_number)
skip = tf.identity(inputs)
# 하나의 residual block을 통과 할 때마다, dimension은 절반으로 줄이고, 채널은 두배로 증가.
# 스트라이드를 통해서 Feature map을 downsampling 합니다.
down = 1
#입력 채널 수와 출력 채널 수가 다르면 차원을 조정, 스킵 연결에 적용되는 1x1 컨볼루션으로 차원을 조정하고, 스트라이드 2를 사용하여 크기를 줄인다
if in_channels != out_channels:
skip = tf.keras.layers.Conv2D(filters=out_channels,
kernel_size=1,
strides=2,
padding="same")(skip)
#만약 차원을 조정해야 한다면, 컨볼루션의 스트라이드를 2로 설정하여 특성 맵(feature map)의 크기를 반으로 줄인다.
down = 2
#첫 번째 3x3 컨볼루션:입력에 3x3 컨볼루션을 적용하고 필요에 따라 다운샘플링한다
x = tf.keras.layers.Conv2D(filters=out_channels,
kernel_size=3,
padding="same",
strides=down)(inputs)
#컨볼루션을 통과한 데이터에 배치 정규화를 적용한다
x = tf.keras.layers.BatchNormalization()(x)
#규화된 데이터에 ReLU 활성화 함수를 적용하여 비선형성을 도입
x = tf.nn.relu(x)
#두번째 컨볼루션 입력
x = tf.keras.layers.Conv2D(filters=out_channels,
kernel_size=3,
padding="same")(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Add()([x, skip])
x = tf.nn.relu(x)
return x-> ResNet 아키텍처에서 볼 수 있는 잔차 블록(residual block)을 정의하는 함수 add_residual_block
잔차 블록(residual block): 딥러닝 아키텍처인 ResNet(Residual Network)에서 사용되는 기본 구성 요소
스킵 연결(skip connection): 신경망에서 입력을 네트워크의 다른 레이어로 직접 전달하는 구조이다.
잔차블록을 정의하는 이유
1.변경이 필요한 부분을 정의하기때문에 학습을 효율적으로 할수있다.
2.깊은 네트워크에서는 기울기(gradient)가 뒤로 전파될 때 점점 줄어들어 사라지는 현상이 발생할 수 있다. 잔차 연결은 이러한 기울기 소실 문제를 완화하여 더 깊은 네트워크의 효과적인 훈련을 가능하게 한다.
3.잔차 블록 덕분에 학습이 안정되고 효율적으로 이루어짐으로써, 이전보다 훨씬 깊은 네트워크를 구축하고 학습할 수 있게 된다
(2) ResNet-18 모델 생성
#이 코드는 모델의 입력을 정의한다. 여기서 입력은 32x32 픽셀 크기의 3채널(RGB) 이미지다
inputs = tf.keras.Input(shape=(32, 32, 3))
#입력 데이터에 첫 번째 컨볼루션 레이어를 적용한다. 이 레이어는 64개의 필터를 사용하고,
#필터의 크기는 7x7이며, 스트라이드는 2이다. 'same' 패딩은 입력과 출력의 공간적 차원을 동일하게 유지한다
data = tf.keras.layers.Conv2D(
filters=64,
kernel_size=7,
strides=2,
padding="same"
)(inputs)
#배치 정규화는 각 레이어의 입력을 정규화하여 학습 과정을 안정화하고 가속화한다.
data = tf.keras.layers.BatchNormalization()(data)
#ReLU(Rectified Linear Unit) 활성화 함수를 적용하여 비선형성을 도입
data = tf.keras.layers.Activation('relu')(data)
#3x3 크기의 윈도우를 사용하여 최대 풀링을 수행한다. 이는 특성 맵의 크기를 줄이고 중요한 정보만을 유지
data = tf.keras.layers.MaxPooling2D(pool_size=(3, 3), padding="same", strides=2)(data)
#각각의 add_residual_block 호출은 잔차 블록을 추가한다
#첫 번째 두 블록에서는 채널 수가 64로 동일하며 차원 변경이 없다.
#다음 두 블록에서는 채널 수를 64에서 128로 증가시킨다.
#그 다음 두 블록에서는 채널 수를 128에서 256으로 증가시킨다.
#마지막 두 블록에서는 채널 수를 256에서 512로 증가시킨다.
data = add_residual_block(inputs=data, block_number='2_1', in_channels=64, out_channels=64)
data = add_residual_block(inputs=data, block_number='2_2', in_channels=64, out_channels=64)
data = add_residual_block(data, '3_1', 64, 128)
data = add_residual_block(data, '3_2', 128, 128)
data = add_residual_block(data, '4_1', 128, 256)
data = add_residual_block(data, '4_2', 256, 256)
data = add_residual_block(data, '5_1', 256, 512)
data = add_residual_block(data, '5_2', 512, 512)
#전역 평균 풀링은 각 특성 맵에 대해 평균을 계산하여 각 맵을 하나의 숫자로 줄인다. 이는 모델의 파라미터 수를 크게 줄이면서도 공간적 특성을 요약한다
data = tf.keras.layers.GlobalAveragePooling2D()(data)
#완전 연결 레이어(Dense)를 통해 모델의 최종 출력을 생성한다. 이 레이어는 10개의 출력을 가지며, 각 출력은 CIFAR-10 데이터셋의 클래스에 해당한다
data = tf.keras.layers.Dense(10)(data)
#입력과 최종 출력을 사용하여 Keras 모델을 생성
model = tf.keras.Model(inputs=inputs, outputs=data)-> ResNet 기반의 이미지 분류 모델을 구축하며, 잔차 연결을 이룬다
inputs = tf.keras.Input(shape=(32, 32, 3)) : 입력은 32*32 픽셀 크기는 3채널이다
data = tf.keras.layers.Conv2D(filters=64,kernel_size=7,strides=2,padding='same')(inputs)첫번째 컨볼루션 레이어
BatchNormalization() : 배치 정규화는 각 레이어의 입력을 정규화여 학습과정을 안정화한다.
ReLU 활성화 함수를 적용하여 비선형성 도입
3*3 크기의 윈도우를 사용하여 최대풀링을 수행 -> 특성 맵의 크기를 줄이고 중요한 정보를 유지
잔차 블록을 추가
전역 평균 풀링
완전 연결 레이어를 통해 모델의 최종출력 생성
***최대 풀링(max pooling)은 신경망, 특히 합성곱 신경망(CNN)에서 사용되는 일종의 다운샘플링 기법이다.특징을 잡아낸 필터에서 특징만을 남긴 이미지이다.
***전역 평균 풀링이란 특성 맵의 각 채널에 대해 전체 영역의 평균을 계산하는 기법이다.
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 16, 16, 64) 9472 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 16, 16, 64) 256 conv2d[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 16, 16, 64) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 8, 8, 64) 0 activation[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 8, 8, 64) 36928 max_pooling2d[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 8, 8, 64) 256 conv2d_1[0][0]
__________________________________________________________________________________________________
tf.nn.relu (TFOpLambda) (None, 8, 8, 64) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 64) 36928 tf.nn.relu[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 8, 8, 64) 256 conv2d_2[0][0]
__________________________________________________________________________________________________
tf.identity (TFOpLambda) (None, 8, 8, 64) 0 max_pooling2d[0][0]
__________________________________________________________________________________________________
add (Add) (None, 8, 8, 64) 0 batch_normalization_2[0][0]
tf.identity[0][0]
__________________________________________________________________________________________________
tf.nn.relu_1 (TFOpLambda) (None, 8, 8, 64) 0 add[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 8, 64) 36928 tf.nn.relu_1[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 8, 8, 64) 256 conv2d_3[0][0]
__________________________________________________________________________________________________
tf.nn.relu_2 (TFOpLambda) (None, 8, 8, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 64) 36928 tf.nn.relu_2[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 conv2d_4[0][0]
__________________________________________________________________________________________________
tf.identity_1 (TFOpLambda) (None, 8, 8, 64) 0 tf.nn.relu_1[0][0]
__________________________________________________________________________________________________
add_1 (Add) (None, 8, 8, 64) 0 batch_normalization_4[0][0]
tf.identity_1[0][0]
__________________________________________________________________________________________________
tf.nn.relu_3 (TFOpLambda) (None, 8, 8, 64) 0 add_1[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 4, 4, 128) 73856 tf.nn.relu_3[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 4, 4, 128) 512 conv2d_6[0][0]
__________________________________________________________________________________________________
tf.nn.relu_4 (TFOpLambda) (None, 4, 4, 128) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 128) 147584 tf.nn.relu_4[0][0]
__________________________________________________________________________________________________
tf.identity_2 (TFOpLambda) (None, 8, 8, 64) 0 tf.nn.relu_3[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 4, 4, 128) 512 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 4, 4, 128) 8320 tf.identity_2[0][0]
__________________________________________________________________________________________________
add_2 (Add) (None, 4, 4, 128) 0 batch_normalization_6[0][0]
conv2d_5[0][0]
__________________________________________________________________________________________________
tf.nn.relu_5 (TFOpLambda) (None, 4, 4, 128) 0 add_2[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 4, 4, 128) 147584 tf.nn.relu_5[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 4, 4, 128) 512 conv2d_8[0][0]
__________________________________________________________________________________________________
tf.nn.relu_6 (TFOpLambda) (None, 4, 4, 128) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 4, 4, 128) 147584 tf.nn.relu_6[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, 4, 4, 128) 512 conv2d_9[0][0]
__________________________________________________________________________________________________
tf.identity_3 (TFOpLambda) (None, 4, 4, 128) 0 tf.nn.relu_5[0][0]
__________________________________________________________________________________________________
add_3 (Add) (None, 4, 4, 128) 0 batch_normalization_8[0][0]
tf.identity_3[0][0]
__________________________________________________________________________________________________
tf.nn.relu_7 (TFOpLambda) (None, 4, 4, 128) 0 add_3[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 2, 2, 256) 295168 tf.nn.relu_7[0][0]
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, 2, 2, 256) 1024 conv2d_11[0][0]
__________________________________________________________________________________________________
tf.nn.relu_8 (TFOpLambda) (None, 2, 2, 256) 0 batch_normalization_9[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 2, 2, 256) 590080 tf.nn.relu_8[0][0]
__________________________________________________________________________________________________
tf.identity_4 (TFOpLambda) (None, 4, 4, 128) 0 tf.nn.relu_7[0][0]
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, 2, 2, 256) 1024 conv2d_12[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 2, 2, 256) 33024 tf.identity_4[0][0]
__________________________________________________________________________________________________
add_4 (Add) (None, 2, 2, 256) 0 batch_normalization_10[0][0]
conv2d_10[0][0]
__________________________________________________________________________________________________
tf.nn.relu_9 (TFOpLambda) (None, 2, 2, 256) 0 add_4[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 2, 2, 256) 590080 tf.nn.relu_9[0][0]
__________________________________________________________________________________________________
batch_normalization_11 (BatchNo (None, 2, 2, 256) 1024 conv2d_13[0][0]
__________________________________________________________________________________________________
tf.nn.relu_10 (TFOpLambda) (None, 2, 2, 256) 0 batch_normalization_11[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 2, 2, 256) 590080 tf.nn.relu_10[0][0]
__________________________________________________________________________________________________
batch_normalization_12 (BatchNo (None, 2, 2, 256) 1024 conv2d_14[0][0]
__________________________________________________________________________________________________
tf.identity_5 (TFOpLambda) (None, 2, 2, 256) 0 tf.nn.relu_9[0][0]
__________________________________________________________________________________________________
add_5 (Add) (None, 2, 2, 256) 0 batch_normalization_12[0][0]
tf.identity_5[0][0]
__________________________________________________________________________________________________
tf.nn.relu_11 (TFOpLambda) (None, 2, 2, 256) 0 add_5[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 1, 1, 512) 1180160 tf.nn.relu_11[0][0]
__________________________________________________________________________________________________
batch_normalization_13 (BatchNo (None, 1, 1, 512) 2048 conv2d_16[0][0]
__________________________________________________________________________________________________
tf.nn.relu_12 (TFOpLambda) (None, 1, 1, 512) 0 batch_normalization_13[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 1, 1, 512) 2359808 tf.nn.relu_12[0][0]
__________________________________________________________________________________________________
tf.identity_6 (TFOpLambda) (None, 2, 2, 256) 0 tf.nn.relu_11[0][0]
__________________________________________________________________________________________________
batch_normalization_14 (BatchNo (None, 1, 1, 512) 2048 conv2d_17[0][0]
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 1, 1, 512) 131584 tf.identity_6[0][0]
__________________________________________________________________________________________________
add_6 (Add) (None, 1, 1, 512) 0 batch_normalization_14[0][0]
conv2d_15[0][0]
__________________________________________________________________________________________________
tf.nn.relu_13 (TFOpLambda) (None, 1, 1, 512) 0 add_6[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 1, 1, 512) 2359808 tf.nn.relu_13[0][0]
__________________________________________________________________________________________________
batch_normalization_15 (BatchNo (None, 1, 1, 512) 2048 conv2d_18[0][0]
__________________________________________________________________________________________________
tf.nn.relu_14 (TFOpLambda) (None, 1, 1, 512) 0 batch_normalization_15[0][0]
__________________________________________________________________________________________________
conv2d_19 (Conv2D) (None, 1, 1, 512) 2359808 tf.nn.relu_14[0][0]
__________________________________________________________________________________________________
batch_normalization_16 (BatchNo (None, 1, 1, 512) 2048 conv2d_19[0][0]
__________________________________________________________________________________________________
tf.identity_7 (TFOpLambda) (None, 1, 1, 512) 0 tf.nn.relu_13[0][0]
__________________________________________________________________________________________________
add_7 (Add) (None, 1, 1, 512) 0 batch_normalization_16[0][0]
tf.identity_7[0][0]
__________________________________________________________________________________________________
tf.nn.relu_15 (TFOpLambda) (None, 1, 1, 512) 0 add_7[0][0]
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 512) 0 tf.nn.relu_15[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 10) 5130 global_average_pooling2d[0][0]
==================================================================================================
Total params: 11,192,458
Trainable params: 11,184,650
Non-trainable params: 7,808
__________________________________________________________________________________________________input_1 (InputLayer): 이 레이어는 모델의 입력을 정의한다. 입력 데이터의 형태는 (None, 32, 32, 3)이며, 이는 높이와 너비가 32픽셀, 채널이 3개인 이미지를 의미한다.
conv2d (Conv2D): 첫 번째 합성곱 레이어는 64개의 7x7 필터를 사용하여 입력 이미지에서 특징을 추출한다. 스트라이드가 2로 설정되어 있어 출력 크기는 (None, 16, 16, 64)가 된다.
batch_normalization (BatchNormalization): 배치 정규화 레이어는 합성곱 레이어의 출력을 정규화하여 네트워크가 더 빨리, 더 안정적으로 학습하도록 돕는다.
activation (Activation): 활성화 함수로는 ReLU(Rectified Linear Unit)가 사용된다. 이 레이어는 음수를 0으로 처리하여, 비선형성을 도입하고, 모델이 더 복잡한 패턴을 학습할 수 있도록 한다.
max_pooling2d (MaxPooling2D): 최대 풀링 레이어는 2x2 풀링을 적용하여 출력의 공간적 크기를 줄이며, 주요 특징은 보존된다. 결과적으로 출력 크기는 (None, 8, 8, 64)가 된다.
conv2d_1 및 conv2d_2 (Conv2D): 이어지는 두 개의 합성곱 레이어는 각각 64개의 필터를 사용하여 이미지에서 더 세밀한 특징을 추출한다. 각 레이어 후에는 배치 정규화와 ReLU 활성화 함수가 적용된다.
tf.identity: 이 레이어는 입력을 변경 없이 출력한다. 이것은 종종 텐서플로우 그래프에서 연산의 이름을 지정하기 위해 사용된다.
add (Add): 이 레이어는 텐서들의 요소별 덧셈을 수행한다. 여기서는 입력과 합성곱 레이어를 통과한 출력을 더하여 잔차 연결을 형성한다.
flatten (Flatten): 플래튼 레이어는 다차원 입력을 1차원으로 평탄화하여 완전 연결 레이어(Dense)에 적합한 형태로 변환한다.
dense (Dense): 완전 연결 레이어는 1024개의 뉴런을 가지고 있으며, 특성을 결합하여 최종 예측을 수행하는 데 사용된다.
dropout (Dropout): 드롭아웃 레이어는 과적합을 방지하기 위해 훈련 중 뉴런의 일부를 무작위로 비활성화한다.
output (Dense): 마지막 레이어는 10개의 출력 뉴런을 가지고 있으며, 각 뉴런은 특정 클래스에 대한 예측을 나타낸다. 활성화 함수로는 소프트맥스가 사용되어 각 클래스에 대한 확률을 출력한다.
-> 생성된 모델을 요약
모델 Compile
model.compile(
# Adam 최적화 알고리즘을 사용하도록 설정한다. Adam은 효율적인 경사 하강법 알고리즘 중 하나로, 학습률을 자동으로 조절한다.
optimizer=tf.keras.optimizers.Adam(0.0001),
#이 라인은 모델이 최적화할 손실 함수를 설정
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
#모델의 성능을 측정할 메트릭을 지정
metrics=["accuracy"]
)-> 모델의 옵션을 설정할 컴파일 과정
Adam 최적화 알고리즘 과 손실함수 성능 측정 매트릭 이 3가지를 지정한다.
***경사 하강법은 모델이 학습하면서 최적의 답을 찾아가는 방법
***손실함수 : 이 함수는 모델이 얼마나 잘못 예측하고 있는지를 수치로 나타내며, 모델 학습의 주된 목표는 이 손실 함수의 값을 최소화하는 것
학습
epochs, validation data set 등 설정
history = model.fit(train_images, train_labels,
#epochs는 전체 훈련 데이터 세트를 몇 번 반복해서 학습할지를 지정
epochs=20,
#batch_size는 한 번에 네트워크를 통과시킬 데이터 샘플의 수
batch_size=128,
#callbacks는 훈련 과정 중 특정 이벤트에 반응하여 실행되는 함수의 목록
# EarlyStopping은 val_accuracy (검증 데이터에 대한 정확도)가 개선되지 않을 때 일찍 훈련을 중단하도록 설정
callbacks=[tf.keras.callbacks.EarlyStopping('val_accuracy', patience=5)],
#validation_data는 훈련 중 모델을 검증하기 위해 사용되는 데이터셋을 지정
validation_data=(test_images, test_labels))Epoch 1/20
391/391 [==============================] - 42s 26ms/step - loss: 1.7499 - accuracy: 0.4140 - val_loss: 1.8137 - val_accuracy: 0.3953
Epoch 2/20
391/391 [==============================] - 10s 25ms/step - loss: 1.0435 - accuracy: 0.6341 - val_loss: 1.3034 - val_accuracy: 0.5500
Epoch 3/20
391/391 [==============================] - 10s 25ms/step - loss: 0.8529 - accuracy: 0.6977 - val_loss: 1.4634 - val_accuracy: 0.5407
Epoch 4/20
391/391 [==============================] - 10s 25ms/step - loss: 0.7157 - accuracy: 0.7489 - val_loss: 0.9883 - val_accuracy: 0.6682
Epoch 5/20
391/391 [==============================] - 10s 25ms/step - loss: 0.6098 - accuracy: 0.7879 - val_loss: 1.0812 - val_accuracy: 0.6434
Epoch 6/20
391/391 [==============================] - 10s 25ms/step - loss: 0.5221 - accuracy: 0.8209 - val_loss: 0.9461 - val_accuracy: 0.6874
Epoch 7/20
391/391 [==============================] - 10s 25ms/step - loss: 0.4419 - accuracy: 0.8453 - val_loss: 1.0196 - val_accuracy: 0.6909
Epoch 8/20
391/391 [==============================] - 10s 25ms/step - loss: 0.3597 - accuracy: 0.8748 - val_loss: 0.8573 - val_accuracy: 0.7244
Epoch 9/20
391/391 [==============================] - 10s 25ms/step - loss: 0.2941 - accuracy: 0.8967 - val_loss: 1.1862 - val_accuracy: 0.6715
Epoch 10/20
391/391 [==============================] - 10s 25ms/step - loss: 0.2440 - accuracy: 0.9143 - val_loss: 1.0623 - val_accuracy: 0.7088
Epoch 11/20
391/391 [==============================] - 10s 24ms/step - loss: 0.1936 - accuracy: 0.9338 - val_loss: 1.1411 - val_accuracy: 0.7124
Epoch 12/20
391/391 [==============================] - 10s 25ms/step - loss: 0.1659 - accuracy: 0.9416 - val_loss: 1.1105 - val_accuracy: 0.7405
Epoch 13/20
391/391 [==============================] - 10s 25ms/step - loss: 0.1466 - accuracy: 0.9490 - val_loss: 1.1460 - val_accuracy: 0.7211
Epoch 14/20
391/391 [==============================] - 10s 25ms/step - loss: 0.1226 - accuracy: 0.9571 - val_loss: 1.2035 - val_accuracy: 0.6994
Epoch 15/20
391/391 [==============================] - 10s 25ms/step - loss: 0.1038 - accuracy: 0.9633 - val_loss: 1.2507 - val_accuracy: 0.7213
Epoch 16/20
391/391 [==============================] - 10s 24ms/step - loss: 0.0938 - accuracy: 0.9674 - val_loss: 1.2084 - val_accuracy: 0.7294
Epoch 17/20
391/391 [==============================] - 10s 25ms/step - loss: 0.0875 - accuracy: 0.9696 - val_loss: 1.8434 - val_accuracy: 0.6684-> 모델 학습을 진행
epoches 훈련을 몇번 반복을 할지, batch_size 로 네트워크를 통과시킬 데이터 샘플수를 정하고 , 특정이벤트에 실행함수를 정한다
batch_size=128 -> 128개의 이미지와 레이블이 한 번에 모델에 입력되어 학습 과정을 거치게 되는 것이다
평가(Evaluation)
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.0, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)313/313 - 2s - loss: 1.8434 - accuracy: 0.6684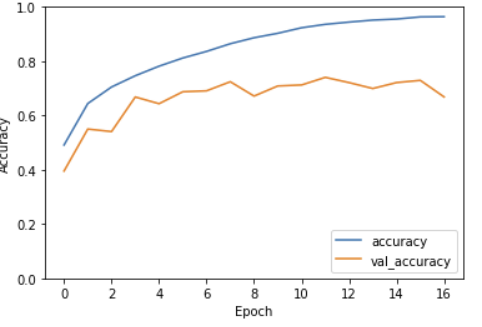
실제 val 데이터에서 0.6정도의 정확도가 나타나있다.
과적합의 징후: 훈련 정확도는 계속해서 증가하는 반면, 검증 정확도는 에폭이 증가함에 따라 향상되는 속도가 느려지고 있다.
전체 프로세스
CIFAR-10 데이터셋을 로드하고 0.0과 1.0 사이의 값으로 정규화
이미지의 이름을 붙이고 이미지 시각화
Residual block 함수 정의
ResNet-18 모델 생성
모델 요약
모델 Compile
모델 학습을 진행
모델 평가 및 시각화
'MOOC' 카테고리의 다른 글
| [딥러닝] 흉부 엑스레이 이미지 폐렴(PNEUMONIA) 분류 실습 (0) | 2024.05.09 |
|---|---|
| [딥러닝] 영화 리뷰 감정 분석 실습 (0) | 2024.05.02 |
| [Deep Learning 5] 파이썬을_활용한_딥러닝_이론_및_실습_중급편_CNN_실습_2 (0) | 2024.04.11 |
| [Deep Learning4]파이썬을_활용한_딥러닝_이론_및_실습_중급편_CNN_실습_1_part5.ipynb (0) | 2024.04.09 |
| [Deep Learning 3] 3-1 최초의 인공지능 Perceptron (1) | 2024.04.07 |